The 2026 AI Crisis: Why Your Enterprise AI Data Pipeline Keeps Crashing
Table of Contents
Summary
Gartner’s 2026 projections say organizations will abandon 60% of their enterprise AI initiatives — not because the technology failed, but because the data was unusable. That number should terrify anyone currently signing off on massive cloud computing bills. We’re building enormous GPU clusters, deploying sophisticated models, and feeding them garbage.
Scarcity isn’t the problem. Unusability is. Your enterprise AI data pipeline is probably starved of operable inputs right now, blocked by compliance walls, missing values, and isolated silos. Unless you fix the underlying state of your data execution architecture, every agentic workflow you stand up this year will collapse in production.
The Compute Binge Hiding a Cracked Foundation

Vertiv just acquired ThermoKey to cool massive AI data centers. Billions going into thermal management and physical infrastructure. Meanwhile, the actual fuel powering these systems? Completely ignored. We’re hyper-optimizing the hardware layer while the data layer rots underneath.
Last month I walked through a client’s facility where the cooling fan noise was deafening. Upstairs, their data science team sat completely blocked. Their enterprise AI data pipeline had stalled because governance wouldn’t release patient records. Servers humming. Lawyers arguing about liability. Expensive machines computing absolutely nothing of value. You can buy all the liquid cooling in the world — it won’t fix data you can’t collect.
Hardware is solved. Data execution architecture is broken.
📃Vertiv to Acquire ThermoKey, Expanding Heat Rejection Portfolio
Why Do 42% of Enterprises Abandon AI Before Production?
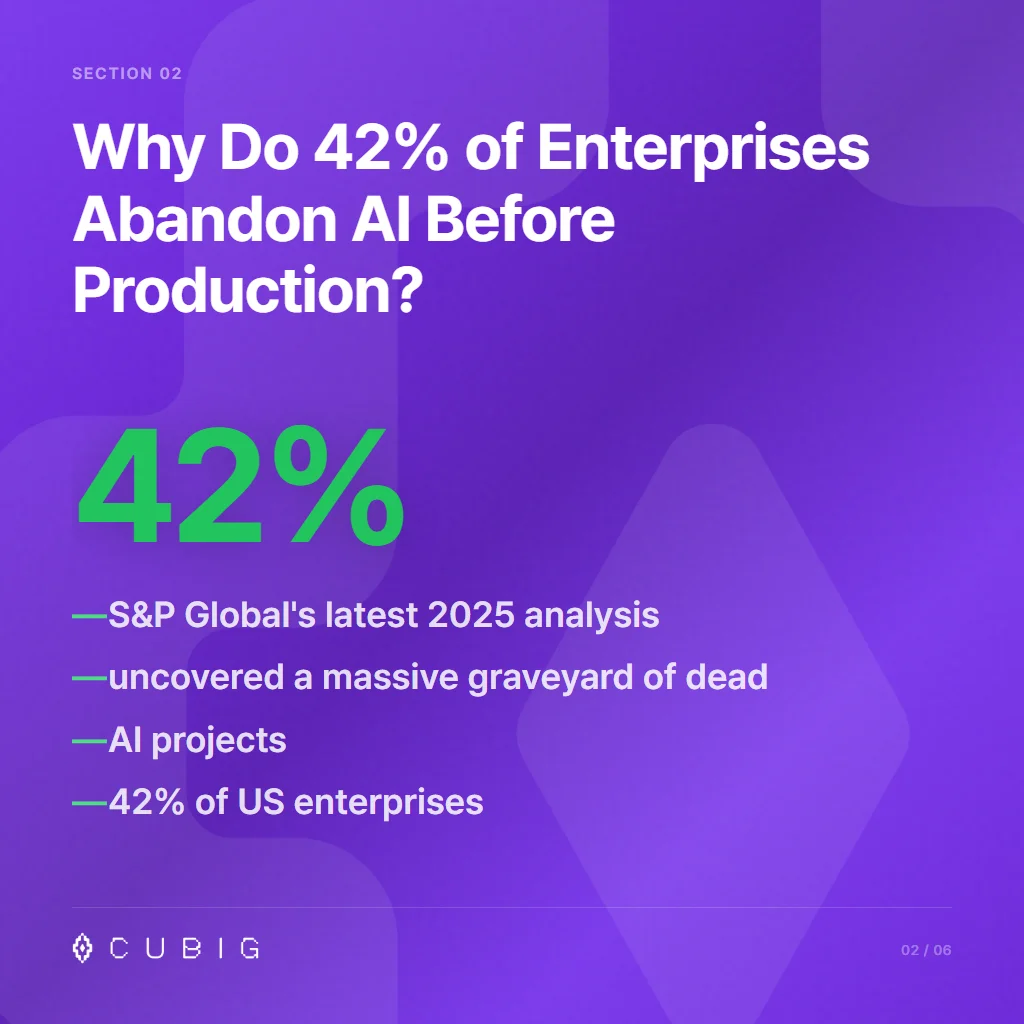
S&P Global’s latest 2025 analysis uncovered a massive graveyard of dead AI projects. 42% of US enterprises abandoned their machine learning initiatives before ever seeing live traffic. Hacker News threads back this up — developers openly admit the hard part is never the algorithm. It’s the sheer chaos of data handling.
Why?
You build a brilliant extraction script on a clean CSV. The stakeholder nods. Then you point that code at a live enterprise AI data pipeline and everything shatters. Production environments expose the raw reality of unusable data.
Tables restricted by regional privacy laws. Historical datasets riddled with nulls and heavy sampling bias. Edge cases you desperately need for safety testing that simply don’t exist in the logs. Enterprise context was missing from the start.
The Dark Data Bottleneck Choking Autonomous Agents

Enterprise dark data utilization is the real battleground this year. IDC research shows 55% of corporate data sits dark and unused. More than half of your company’s institutional knowledge, trapped in unstructured formats machines can’t natively read.
Capital One recently started using tokens to turn dark data into an AI asset, according to SiliconANGLE. They get it — storing unusable files is just a massive corporate liability. Pulling real value out requires data restructuring that makes those files legible to language models. Skip this step, and your shiny new autonomous systems starve for context.
“Give an agent unusable data, and it hallucinates at scale.”
That 55% figure from IDC? It represents the primary bottleneck for deploying agentic AI in production. Agents built on Model Context Protocols depend entirely on what you feed them. One data engineer on Reddit put it bluntly: deep domain knowledge now matters far more than raw coding skills. AI needs business logic, and that logic is currently buried in PDF silos and legacy databases.
📃Enterprise data security aims to secure dark data for AI – SiliconANGLE
What Happens When Agentic Loops Hit Trapped Data?

Autonomous systems amplify poor data quality at machine speed. Terrifying machine speed. Forrester’s 2026 Data Quality Wave report flagged this exact threat — agentic AI data quality needs to be flawless. A single error in an automated loop compounds instantly, with no human in the chain to catch it.
A traditional reporting tool just shows a wrong number when the database breaks. An agentic loop takes that wrong number, emails a client, updates a downstream CRM, and triggers a billing workflow. All before anyone blinks. You can’t run autonomous processes on an enterprise AI data pipeline built for monthly batch reporting.
The foundation is cracked. Usable data barely exists in most corporate environments today.
The Hacker News Reality Check on Federated Learning

Developers are catching on: distributed training doesn’t solve data unusability. A massive Hacker News discussion recently tore apart the idea that federated learning is a silver bullet. Moving the model to the data doesn’t help when the data itself is garbage. Worse, the community flagged a glaring vulnerability — input data can actually be reverse-engineered directly from model weights.
AI data restructuring vs masking has become a mandatory technical debate for engineering teams. Simple masking or tokenization won’t cut it anymore. You can’t just redact a few columns and hope the model doesn’t memorize sensitive patterns. True original-replacement data generation is the only path to safe, production-ready systems.
By transforming unusable unstructured data into original-replacement data generation assets, data leaders can block the reverse-engineering vulnerabilities that keep surfacing in modern LLM research.
Why Your Data Team Keeps Rebuilding the Same Pipeline
Countless sprints, wasted on custom scripts for broken sources. Dnotitia just launched a SaaS platform dedicated entirely to advanced data preprocessing — because the market is that desperate for data pipeline bottleneck solutions.
Look at your current enterprise AI data pipeline. One tool parsing messy text. Another handling missing values. A third trying to enforce regional compliance rules. The architecture becomes a house of cards. When an upstream schema changes, the entire pipeline crashes at 2am. Sound familiar?
“We spend 80% of our time wrangling data unusability instead of building actual features.”
Production models crash because of data state at execution time. Rarely the algorithms. You need a unified approach to transforming unusable data for AI, or your team will keep rebuilding the same fragile ingestion layers forever.
📃Dnotitia Launches Seahorse Cloud to Accelerate Enterprise AI Deployment
The Shift From Unusable to Operable Data
Local marketing agencies are already deploying AI-ready website structures. Utah Marketers recently announced frontend frameworks built specifically for machine reading. If small shops are structuring their public data for AI, enterprise teams have zero excuses for keeping backend data locked in silos. The baseline expectation has shifted across the entire industry.
An enterprise AI data pipeline needs to do more than shuttle bytes from point A to point B. It has to actively cure bias, handle rare events, and restructure regulation-trapped tables into regulation-friendly formats.
The goal is data activation — turning trapped liabilities into operable assets.
📃Utah Marketers Announces AI-ready Custom Website Design
How CUBIG Addresses This
If you’ve ever tried getting approval for AI training data and slammed into a wall of compliance objections, you know this frustration firsthand. Data everywhere. Messy, incomplete, trapped behind internal regulations. Models starving while storage bills climb.
SynTitan is the engine that finally closes this gap. It takes your messy, regulation-trapped data and makes it usable — without exposing a single sensitive record. Missing values and historical biases get automatically cured before they ever touch your models.
Picture your Monday morning. Instead of writing custom Python scripts to clean spreadsheets or arguing with governance boards, your team runs models on an enterprise AI data pipeline that’s already verified and ready. Results are captured in immutable release states, so you always know exactly what data fed what model. Your team finally gets to build AI instead of playing digital janitor.
FAQ
Why do data teams struggle to feed agentic AI models?
Most legacy infrastructure was built for batch reporting, not autonomous systems. An enterprise AI data pipeline needs to deliver pristine, context-rich information in real-time. When agents ingest missing values or broken formatting, they hallucinate wildly. You have to fix data unusability at the root before giving an agent read-access to your corporate database.
How does data restructuring differ from basic column masking?
Masking just hides specific values — and often breaks the underlying statistical relationships, ruining model accuracy. Data restructuring completely rebuilds the dataset into original-replacement data. It preserves the exact statistical distribution and structural integrity of the original tables without ever exposing actual sensitive records.
What makes an enterprise AI data pipeline production-ready?
A production-ready pipeline doesn’t just transport information. It actively transforms unusable data into a verified state. Missing values, biased samples, inconsistent formats — all handled automatically during ingestion. By the time data reaches your machine learning models, it should be fully operable and regulation-friendly.
How can SynTitan help recover failed machine learning PoCs?
Most PoCs die because production data is vastly messier than the clean staging environment. SynTitan auto-cures missing variables and restructures trapped data into a usable format. Your enterprise AI data pipeline runs on clean, AI-ready states — without exposing raw internal records to the models.
Why is dark data such a high risk for AI deployments?
Roughly 55% of corporate knowledge sits trapped in unstructured, dark formats. Ignore enterprise dark data utilization and your models lack crucial business context. But feeding raw dark data into an LLM often exposes trade secrets and undocumented liabilities. The data has to be activated and restructured first.
How do we prevent model weights from being reverse-engineered?
Training directly on raw, sensitive records lets attackers extract original inputs from the final model weights. The fix: original-replacement data generation. If the model never sees actual raw records during training, those records simply can’t be reverse-engineered later. The attack surface disappears.

CUBIG's Service Line




Recommended Posts


