
Why AI Fails After Deployment : Execution Conditions Change
Table of Contents

The question every AI team eventually asks
Across industries, organizations that have moved AI into production share a strikingly consistent experience.
“The results that worked fine yesterday are acting strange today.” “Same data input — completely different output.” “We didn’t change the model. Performance just dropped.”
At first, it looks like a bug. But when this happens repeatedly, a deeper question emerges inside the organization:
“Can we actually trust this output? Can we base a real decision on data this unstable?”
The moment that question surfaces, AI stops being a decision tool. It gets demoted to a reference document — consulted in meetings, then set aside when the real choices are made. According to McKinsey’s The State of AI in 2025, companies that have fully scaled AI enterprise-wide remain a small minority.

The model is fine. So why do outputs keep drifting?
When an AI project reaches production, the early results are usually encouraging. The model trains cleanly, test environments return expected performance, and the team ships with confidence.
Then real-world usage begins — and results start to shift. Same inputs, different outputs. Errors that appear only in specific edge cases. Performance that degrades without any obvious cause.
The team starts asking: is it the model? The data? A pipeline issue? The question itself is the symptom. There’s no reference point to compare against — no baseline data state to audit.
The three causes of post-deployment AI failure
Distribution Shift The statistical properties of incoming data diverge from training data over time.
Input Schema Change Column structures, field types, or data sources change — silently, incrementally.
Preprocessing Inconsistency Different teams apply different transformation logic to the same raw data.
What is commonly called data drift is not a single event — it is the cumulative effect of these three forces operating simultaneously and silently. The problem is not that change happens. The problem is running AI in an environment where change cannot be tracked, explained, or attributed.
Data isn’t missing. It’s unusable.
Most enterprises believe they have enough data. In practice, the issue is rarely volume. The issue is usability state.
- Rare-event data — the high-value signals organizations need most occur infrequently in real operational data
- Regulated data — critical datasets are locked behind compliance and access restrictions
- Structurally misaligned data — existing data has quality or schema issues that make it incompatible with model requirements
The result: AI systems are deployed on top of data that was never actually ready. Not because the data team was negligent — but because no framework existed to continuously assess and maintain data in an AI-executable state.
The bottleneck in enterprise AI is not model capability. It is the gap between data that exists and data that is usable.
AI-Ready is not a one-time preparation. It’s an ongoing state.
The instinct, when confronted with data quality problems, is to run a data cleaning project. Standardize formats. Remove duplicates. Fill missing values. Ship.
The problem: data doesn’t hold still. New data arrives with different distributions. Upstream systems change their schemas. Business questions evolve. What was AI-Ready last month may be AI-degraded today.
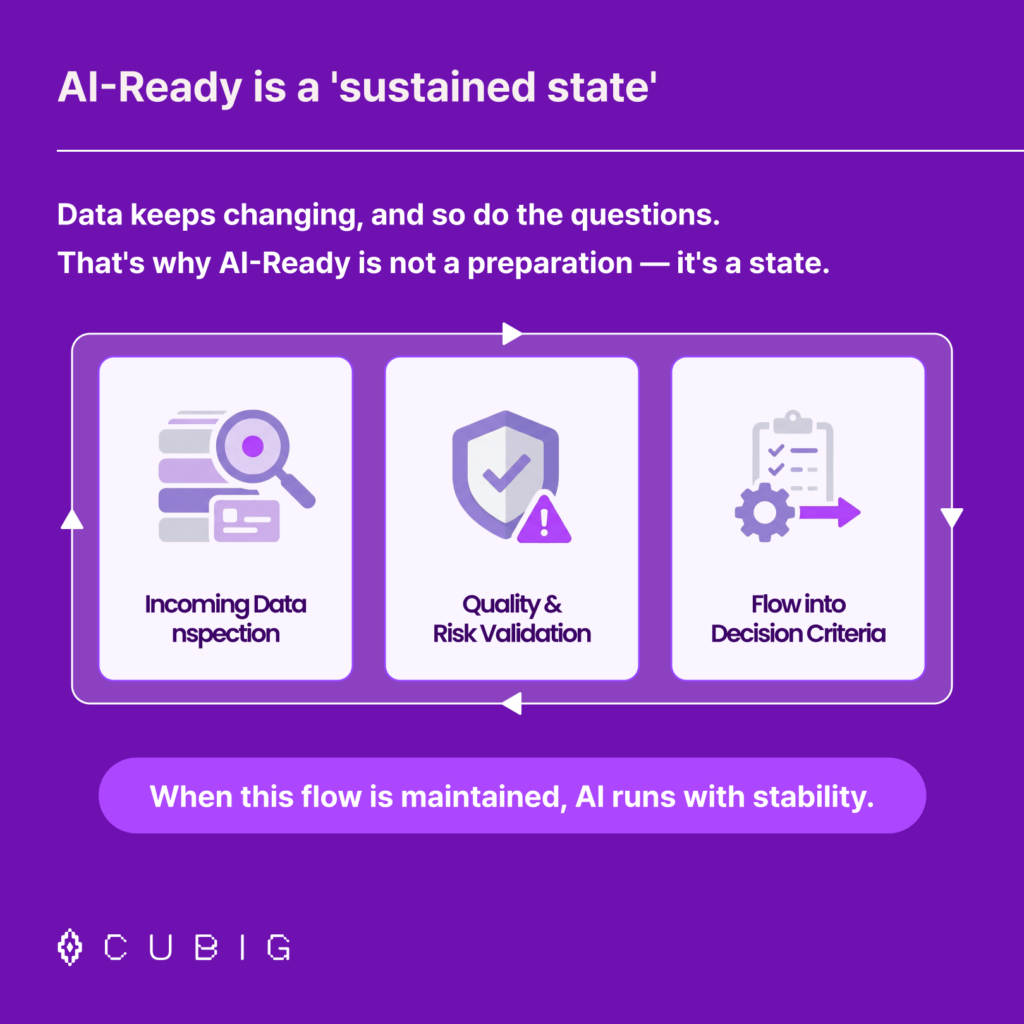
AI-Ready is not a state you achieve once. It is a state you maintain continuously.
This means building a flow that operates on every new data input:
- Incoming data is inspected at the point of entry
- Quality and risk factors are validated before execution
- Results are traced back to the data state that produced them
- Insights from each cycle feed the standards for the next
When this loop runs continuously, AI outputs are no longer mysterious. They are explainable. And explainable outputs become trustworthy decision inputs.

SynTitan: connecting data state to execution in a single traceable flow
The root cause of post-deployment AI failure is the separation between data state and AI execution. Most organizations have no unified view of what state their data was in when a result was produced — so when outputs change, they cannot explain why.
SynTitan by CUBIG addresses this at the infrastructure level.
01 — Data Ingestion Data is already different the moment it arrives. SynTitan captures source origin, generation timestamp, and data structure at point of entry.
02 — Data State Profiling Before AI execution begins, data state is profiled and validated — not assumed. Distribution & patterns / Missing values & outliers / Structural changes
03 — Policy & Transformation Data is never used as-is. Policy-based handling ensures sensitive data, usage scope, and access controls are applied consistently.
04 — Execution Layer AI runs on top of the verified data state. Execution conditions are logged alongside model outputs.
05 — Result Tracking & Feedback Outputs are stored alongside the data state that produced them — enabling output variance analysis and continuous improvement.
The result: “why did this output change?” has an answer. Data quality breakpoints are visible. State changes are attributable.
FAQ
Q. Why does AI fail after deployment even when the model is good? Post-deployment AI failure is almost always a data state problem, not a model problem. When the statistical properties of incoming data shift — through distribution change, schema updates, or preprocessing inconsistency — the model’s learned representations no longer match the inputs it receives. The model hasn’t changed. The data environment has.
Q. What is data drift and why does it matter for enterprise AI? Data drift refers to changes in the statistical properties of input data over time. For enterprise AI systems operating on live business data, drift is inevitable. The issue is not drift itself, but the absence of systems to detect, track, and attribute it.
Q. What does it mean for data to be “AI-Ready”? AI-Ready means data is in a continuously validated, policy-compliant, structurally consistent state that allows AI models to execute reliably. It is not a one-time data preparation exercise — it is an ongoing operational state.
Q. How does SynTitan address post-deployment AI instability? SynTitan connects data state to AI execution in a single traceable flow — from ingestion and state assessment through governed processing, model execution, and output tracking. Every result is linked to the data state that produced it, making output variance explainable rather than opaque.

If your AI project keeps breaking down
— check the data state, not the model. SynTitan connects data state to AI execution in a single traceable flow.

CUBIG's Service Line



Recommended Posts


