- Consultants define “AI-ready”
- A six-month readiness project
- PoC after PoC
- Agents stall on the data
- “We hope it works”
Syntitan · AI-Ready Data Platform
Stop hoping it works in production. Prove it on your own data.
The model isn’t the problem. Your data is. Syntitan gets your data AI-ready, then proves the difference before production.
Free trial on sign-up. No sales call, no PoC.
Old vs new
Stop getting AI-ready. Just be AI-ready.
No consultants, no readiness workshops, no vibe checks. Sign up and run it.
- Sign up, no sales call
- A six-axis readiness score in 30 seconds
- A working product, not a PoC
- Agents get sharper on the same data
- Reproduce it yourself with a hash
Verifiable Data State
Your AI doesn’t break on the model.
Your AI doesn’t break on the model.
It breaks on the data state.
A run that worked yesterday breaks today, and no one can point to what changed. Syntitan controls the data state behind every AI run, then ties it to model performance you verify yourself.
Release State
Freeze the exact data state an AI used. “What data did we train on in March?” gets a one-click answer for audit.
Run Binding
Every AI run is bound to a data state, so “this result came from this exact data” is traceable automatically.
Diff
Compare yesterday’s and today’s data. When output drifts, see in seconds whether the data changed.
Reproduce
Restore any past state and re-run it. “Worked in March, broke in April” becomes a reproducible investigation, not a guess.
AI-ready
AI-ready isn’t one thing.
AI-ready isn’t one thing.
It’s six measurable axes.
AI Readiness Qualification checks whether data can be reliably and traceably used by models or agents.
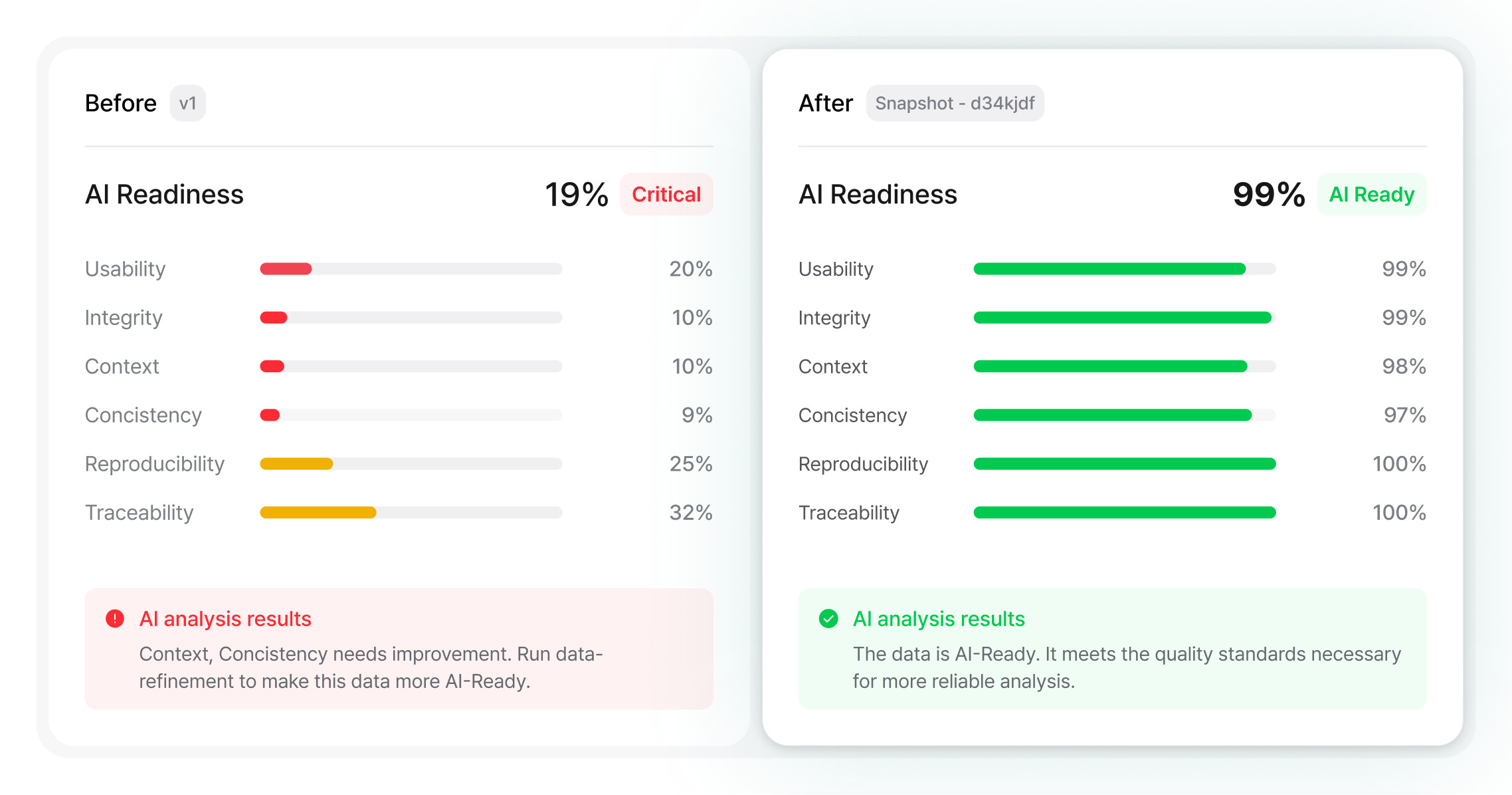
Usability
Can sensitive data be used with AI safely?
Integrity
Are missing values, duplicates, and skew visible?
Context
Does AI know what each field means?
Consistency
Which fields help or hurt the AI task?
Reproducibility
Can this data state be reused in a workflow?
Traceability
Can changes, versions, and authors be tracked?
Product
From data diagnosis to verified proof.
From data diagnosis to verified proof.
One workspace.
Walk through the real Syntitan product, from data diagnosis to model verification. Pick any step to open its workspace.
AI Readiness Diagnosis
Diagnose whether your data is ready for AI across six axes, and pinpoint what to fix first.
Overall AI Readiness
61%Caution
AI analysis results
AI readiness is partial. Integrity (34%) and Context (30%) are critically low. Fix these before training. The other four axes pass.
Proof Run
Run the before/after data through a baseline model to preview the expected impact of AI-ready prep.
Preview Setup
XGBoost baseline
Binary classification
Recall @ fixed precision
Snapshot vs AI-Ready Release
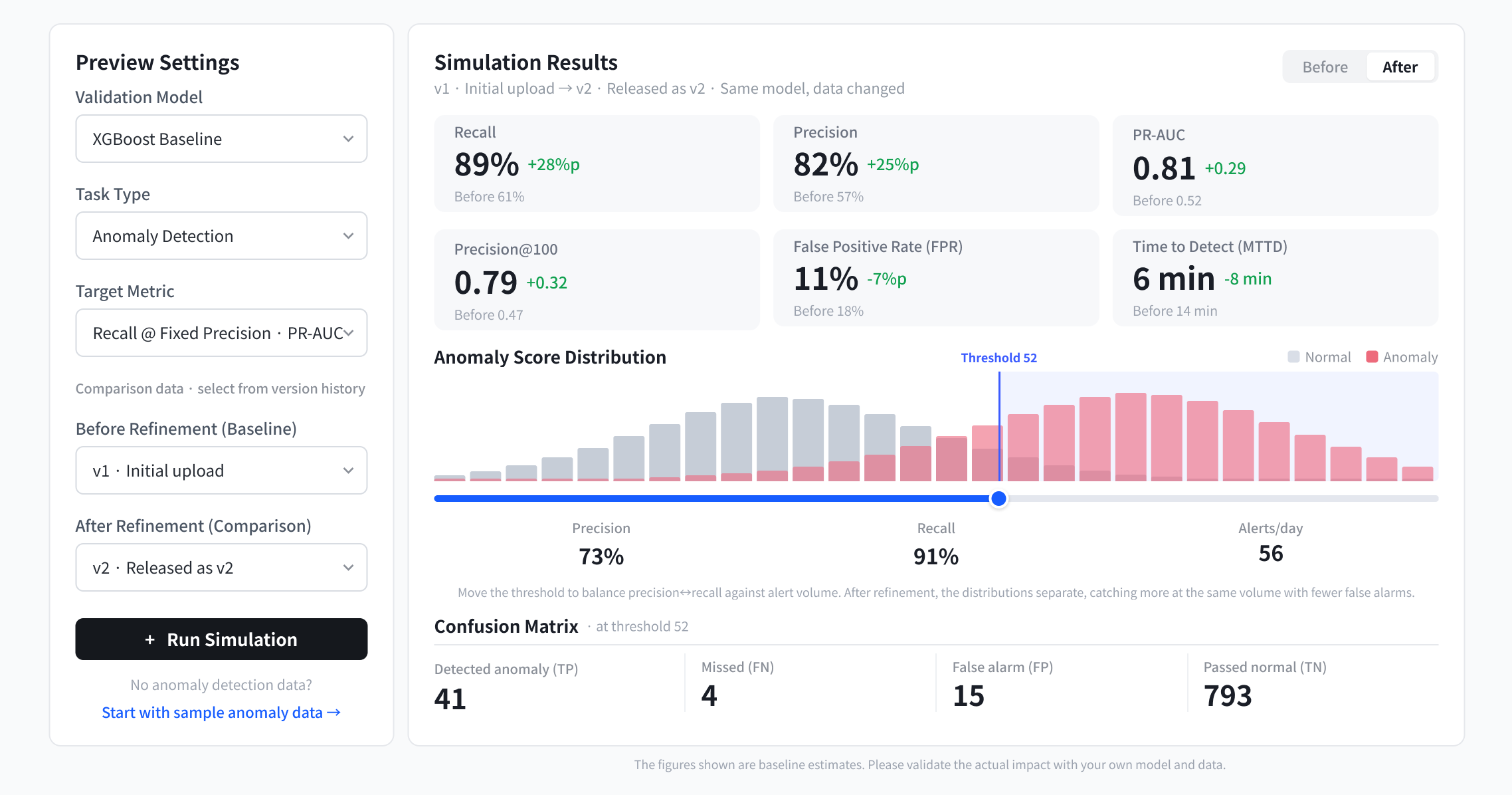
Simulation Result
Before · Raw data
Approve transaction
Recall61%
F10.64
False positive18%
After · AI-ready
Flag for review
Recall89%
F10.78
False positive11%
Expected uplift
Recall+28 pts
F1+0.14
False positive-31%
No model yet?
Get an instant read with a standard baseline model. Figures shown are baseline estimates. Verify the real impact with your own model.
Optimize for My Model
Adjust the AI-ready prep priorities to your model’s target metric and evaluation data.
Upload eval dataset
Connect an evaluation dataset that includes ground-truth labels.
Upload prediction result
Upload the prediction output from your current production model.
Connect model via MCP
Connect model execution from Claude Code or your own environment.
✓ Auto-detected Fraud detection · Target metric: Recall @ 95% precision · Current score: 73%
Optimization Plan
Handle PII columns
Substitute sensitive columns to stabilize model inputs.
Remove duplicate records
Remove duplicates that bias training.
Standardize schema context
Normalize column semantics and link them to task intent.
Drop noisy columns
Drop unused columns to cut token cost and noise.
Not generic cleanup. We prioritize the prep that moves your model’s performance the most, in order of impact. Uplift figures are baseline estimates; your validated lift is reproduced on your own model.
AI-Ready Enhancement
Fix data values and distribution, and add the context AI needs to use the data.
Feature derivation & augmentation
Creates new columns through binning and categorization, and adds composite signals via cross-column operations.
Sensitive data detection & substitution
Replaces sensitive values with non-identifiable ones.
Missing value treatment
Preserves meaningful missingness patterns as signal and fills the remaining gaps with statistical methods.
Outlier, distribution & category refinement
Detects outliers and corrects distribution and category skew so models train reliably.
Data augmentation & class balancing
Generates synthetic samples for minority classes and rebalances class ratios to a normal range.
Low-signal column removal
Selectively removes low-importance columns and those that could contaminate predictions.
Release & Run Binding
Freeze the AI-ready result as a versioned Release State. Every AI run binds to it.
New Release
This will be published as v4.
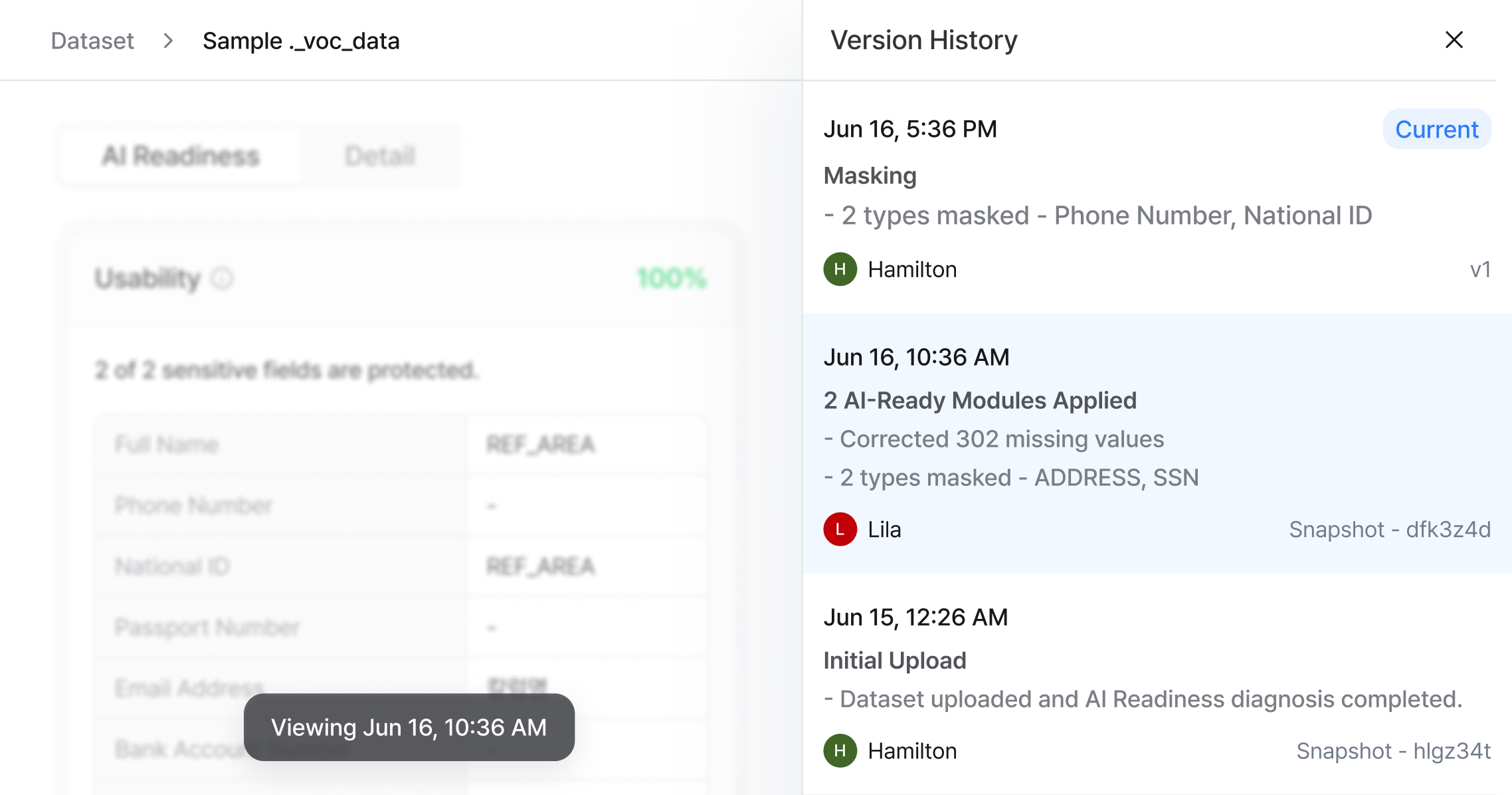
Version History
Jun 30, 6:27 PM
Sensitive fields handled. Column meaning added for product_category. Distribution stable vs v2.
Jun 27, 11:18 AM
Class balancing applied · low-signal columns removed
Jun 27, 10:16 AM
Initial upload
v3 released successfully.
Verify via Claude MCP
Don’t just take Syntitan’s word for it. Re-run it yourself under identical model, seed, and split, in your own environment.
Portable Proof Kit
before_snapshot.csvready
after_release.csvready
change_manifest.jsonready
comparison_harness.pyready
eval_config.jsonexportable
README.mdexportable
Claude MCP
Open Claude Code
Verification ready
Run the before/after data in Claude Code and reproduce the result.
Not just a data download. Export a reproducible experiment kit bundling the Change Manifest, Harness, and Eval Config.
Proof
The proof is in the product.
Three screens from the product that prove the AI which passed your PoC keeps working in production.
Three ways to run a proof.
Pick whichever fits how you work: bring your own model, tune the prep to your metric, or re-run it yourself.
Preview with a baseline
No model of your own? Syntitan’s baseline model compares before and after performance instantly.
Optimize for your model
Syntitan tailors the data-prep direction to your target metric, eval set, and model.
Verify via Claude MCP
Export the before/after, change manifest, and harness to re-run in your own environment.
Platform
DTS and LLM Capsule live inside Syntitan.
Syntitan is the platform; DTS and LLM Capsule are its core capabilities. You adopt one platform for AI-ready execution, not three tools.


Platform
Syntitan
Diagnose data readiness, release a fixed AI-ready state, and bind every run to it, so what worked in the demo holds in production.
DTS
Rebuild restricted, imbalanced, or blocked data into AI-ready datasets, so the data you couldn’t use becomes data your model can.
Learn moreLLM Capsule
Run AI on sensitive data with its context preserved, then restore the results inside your own workflow.
Learn moreHow the platform puts them to work
Validation
Score whether the data DTS and Capsule produce is AI-ready on six axes, and preview the lift on your model before production.
Verifiable Data State
Lock that data state to a version so every run reproduces exactly. Release · Run Binding · Diff · Reproduce.
Agent connection
Hand the verified data state to every agent via Claude MCP, so outputs stay bound to data you can trust.
Agents
Agents that run on ready data, not guesswork.
Generic agents guess from assumptions. Syntitan agents run on qualified data states, grounded with semantic context attached.
100K synthetic personas that reproduce real response distributions
Generate survey responses from synthetic personas and analyze behavior patterns.
Result report
Which customers to focus on, simulated down to ROI
Segment customers by behavior and demographics, and simulate ROI-based strategy.
Result report
Catch churn signals before customers leave
Identify at-risk customers from behavioral signals, predict churn, and suggest retention strategy.
Result report
Launch-price simulation that pre-validates revenue and churn impact
Analyze price sensitivity and recommend a launch price that accounts for revenue and churn impact.
Result report
Already have a model or agent?
Through API connection, we compare performance before and after AI-Ready.
Book architecture reviewCan't find the agent you need?
Tell us your analysis scenario and we'll design a custom agent.
Book architecture review
Fit
Where Syntitan fits in your AI data stack
Syntitan does not replace the tools your team already runs. It fills the missing step between enterprise data and AI execution.
Syntitan in one line
The path from raw enterprise data to a fixed, traceable AI-ready data state for production AI and agentic workflows, with data provenance attached.
-
Data platforms
Store enterprise data: warehouses, lakehouses, pipelines.
Syntitan addsThe AI-ready data state on top: qualification, enhancement, release.
-
Data quality tools
Detect issues: null rates, type errors, schema drift.
Syntitan addsAI readiness qualification, semantic enhancement, and a fixed Release State.
-
Observability tools
Detect that something changed in pipelines, models, or systems.
Syntitan addsWhich data state changed: Diff between Release States, reproduce the prior one.
-
Agent tools
Run agents and agentic workflows on top of data.
Syntitan addsA prepared data state for agents to run on, with outputs grounded, not guessed.
-
Sensitive-data transformation tools
Synthetic transformation and sensitive-data preparation.
Syntitan addsOne entry path in a broader workflow: Diagnose → Enhance → Release → Run Binding → Trace.
Use cases
Where your team starts
Wherever your team begins, the path lands on the same Release State.
When AI breaks, how do you know if the cause is data or execution?
Run Binding, Release State, and Diff narrow the cause from evidence, not memory.
Can you prove which data state produced this result?
Every risk analysis is bound to a Release State with version history that internal review can inspect.
Can you recreate the exact segment used in the last campaign?
Release campaign data states and compare before-and-after changes across versions.
How long does it take to reproduce last month's analysis?
Recurring analysis stays attached to the same Release State, so reproduction is a click, not a rebuild.
Do prediction results change every quarter without a clear reason?
Prepare sensitive workforce data through a restricted-data path, release the analysis state, then compare quarter to quarter.
FAQ
Frequently asked questions
Syntitan is an AI-Ready Data Platform that helps enterprise teams diagnose data readiness, enhance data and context, prepare restricted data, release fixed AI-ready states, and trace every AI or agent run back to that state.
An AI-Ready Data Platform prepares enterprise data for AI use by qualifying readiness, enhancing data and context, preparing restricted data, and binding production AI runs to fixed data states.
Most enterprise data is not ready yet. Syntitan scores your data readiness for AI across usability, integrity, context, and traceability, then shows the specific gaps blocking model or agent use before you spend weeks cleaning data.
Syntitan qualifies data readiness, enhances data values and context, prepares restricted data, and fixes the result as a released AI-ready state that every AI or agent run can bind to.
AI Readiness Qualification checks whether data can be reliably and traceably used by AI models or agents. It surfaces gaps across Usability, Integrity, Context, Consistency, Reproducibility, and Traceability.
AI-Ready Enhancement fixes data values, distribution, and class balance, and adds the context AI systems need to understand what the data means.
A Release State is a fixed AI-ready data state. Once released, it becomes the reference point for analysis, agent runs, and operational review.
Run Binding connects every AI or agent execution to the Release State used for that run.
Diff compares two Release States to narrow down what changed between them. Reproduce restores a previous data state so teams can investigate from evidence.
Syntitan can compare live production data against a released AI-ready baseline and surface which fields and distributions have moved.
Syntitan agents and agentic workflows run on qualified, data-grounded states with semantic context attached, not on raw files. Their outputs share the same Release State every team uses.
Data platforms store and process data. Data quality tools detect issues. Observability tools detect that something changed. Syntitan sits between them and AI execution: it qualifies whether the data is ready, enhances data and semantic context, fixes the state as a Release State, and binds every AI or agent run to that state. Other tools describe or detect. Syntitan prepares.
For selected design partners, Syntitan can preview whether internal data has the signal and context required for a target model, before full evals are run.
Which data state is your AI running on?
Most teams can’t answer. In one upload, Syntitan can.