Synthetic Data: The AI Trend Leading Organizations Can’t Ignore
Table of Contents

Hello! We’re CUBIG, a company dedicated to helping organizations navigate the balance between data protection and data utilization. 😊
Synthetic data replicates the statistical properties and patterns of original datasets—without containing any actual personal or sensitive information. Think of it as data that “works like the real thing, but isn’t.” It opens up possibilities for analysis, machine learning, and collaboration without directly sharing or exporting raw data.
Globally, synthetic data is no longer viewed as a “nice-to-have.” It’s increasingly treated as foundational infrastructure for AI operations. From autonomous vehicles to healthcare, finance, and the public sector, industries where data is mission-critical are adopting synthetic data at a rapid pace.
In this post, we’ll explore why synthetic data adoption is accelerating worldwide, how it’s being applied across industries, and what your organization should consider before implementation. We’ll also share how CUBIG’s synthetic data technology fits into this evolving landscape.
🌍 Why Has Synthetic Data Become Essential?

When organizations try to adopt AI today, the biggest obstacle usually isn’t “we don’t have the right model.” More often, it’s “we can’t actually use our data.”
Raw datasets contain personal information and sensitive details. Sharing across departments is complicated. External PoCs and research collaborations become even more delicate. In this environment, leading markets have shifted their perspective: synthetic data isn’t optional—it’s a prerequisite for running AI.
Gartner projects that by 2030, synthetic data will surpass real data in AI model training.
📈 Three Forces Driving Market Growth
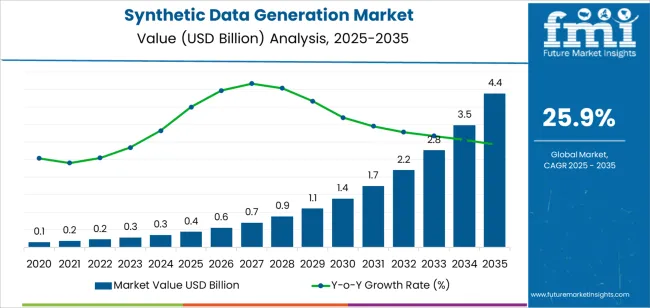
The synthetic data market is expanding rapidly, driven by three key factors:
First, high-quality training data is scarce. Collecting and labeling AI-ready data is time-consuming and expensive. Edge cases and rare scenarios are often impossible to source from real-world data alone.
Second, privacy regulations are tightening. As data privacy laws strengthen worldwide, using raw data directly is becoming increasingly difficult. Organizations need alternatives that enable analysis, training, and validation without exposing sensitive information.
Third, simulation-based development is on the rise. As AI agents and simulation-driven development grow more prevalent, the ability to generate and validate data securely—without compliance risks—is becoming essential.
Market projections reflect this momentum. According to Future Market Insights, the synthetic data generation market is expected to grow from approximately $400 million in 2025 to $4.4 billion by 2035. While exact figures vary by source, the trajectory is consistent: this market is experiencing significant growth.
🧪 Real-World Applications: Synthetic Data in Action

Synthetic data isn’t an abstract concept—it’s already transforming development practices across industries.
🚗 Autonomous Vehicles & Mobility Self-driving systems can’t endlessly test dangerous scenarios on real roads. Simulation is essential. Waymo has reported logging over 20 billion miles in simulated environments. Synthetic data enables training on edge cases that would be impractical or impossible to recreate in the real world.
🏥 Healthcare & Medical Research Patient data is highly sensitive and difficult to share. Synthetic patient data allows researchers to validate hypotheses quickly and create secure datasets for collaboration—without compromising privacy.
💳 Finance & Risk Management Fraud detection and anomaly analysis require diverse scenario data. Organizations need structures that enable model validation and external collaboration without exposing original transaction records containing customer information.
🏛️ Public Sector & Open Data Public data initiatives aim for openness, but personal information creates barriers. Rather than releasing raw data, creating “releasable formats” through synthetic data has become a practical solution. Synthetic data also plays a central role when inter-agency data sharing is required.
🧾 The Regulatory Shift: From Prohibition to Conditional Approval

When people think of AI regulation, “restriction” or “prohibition” often come to mind first. But recent regulatory trends tell a different story. The focus isn’t on stopping AI use—it’s on ensuring proper safeguards are in place.
The EU AI Act is a prime example. Requirements for high-risk AI systems don’t simply prohibit AI use. Instead, they mandate governance frameworks covering data quality, representativeness, and bias detection and mitigation. The question organizations must answer has shifted from “Can we use AI?” to “What data controls and validation systems do we have in place?”
This trend extends beyond Europe. Privacy breach reports are increasing rapidly, while public sector evaluations are placing greater emphasis on AI-ready data, data quality, and utilization outcomes. Organizations face simultaneous pressure to strengthen data protection and expand data utilization.
The implication is clear: organizations need approaches that protect original data while producing usable formats for analysis and training. This is precisely where synthetic data becomes critical.
✅ A Practical Checklist for Synthetic Data Adoption

Before implementing synthetic data, there are key questions to address. Working through this checklist can significantly reduce trial and error in creating AI-ready synthetic data.
1. Define Your Purpose First Start with “why”—not “what.” Whether the goal is AI model training, internal testing, inter-agency sharing, or public release, the required quality standards and acceptable risk thresholds vary significantly. Internal testing may tolerate some quality trade-offs, but public release demands much stricter re-identification risk standards.
2. Quantify Data Utility Even the safest synthetic data is meaningless if it can’t be used effectively. You need to answer questions like “How statistically similar is this to the original?” and “How well are analytical results preserved?” with concrete metrics. Replace “It’s similar” with “Distribution differences for key variables are within 5%.” Quantifiable evidence makes internal stakeholder buy-in easier and strengthens your position during audits and evaluations.
3. Document Safety with Metrics “It’s synthetic, so it’s safe” is no longer sufficient. Document your methodology: How was re-identification risk measured? What attack scenarios were considered? Under what conditions was safety determined? Regulatory bodies and audit teams increasingly demand logical justification for safety claims. Maintaining quantitative evaluation results alongside decision criteria protects your organization down the road.
4. Design Your Operational Framework Synthetic data isn’t a one-time project—it requires ongoing generation and management. Consider: Where is original data processed (on-premise, air-gapped networks, cloud)? Do external vendors access original data? Who has authority to generate and export synthetic data, and under what permissions? Even technically excellent synthetic data loses credibility if operations expose original data or access controls are weak.
🚀 CUBIG DTS: Secure Generation, Immediate Utility

CUBIG’s DTS (Data Transform System) brings globally recognized synthetic data capabilities into practical, deployable form for enterprises and public institutions. DTS is infrastructure that generates secure synthetic data from your organization’s original datasets—ready for analysis, sharing, and release. Here’s how it addresses common real-world challenges:
Original data stays in place. In regulated industries and public sector environments, a “no-export architecture” significantly reduces risk. It creates space for data utilization discussions to shift from “prohibited” to “conditionally approved.”
Quality and safety become demonstrable. Synthetic data generation is just the beginning. Internal decision-makers and auditors need to see evidence that the data is both useful and safe. DTS includes validation workflows that enable organizations to make informed judgments and maintain proper documentation.
Data sharing and release become achievable. Public institutions face growing pressure for open data and AI adoption. Enterprises need faster collaboration and PoC cycles. DTS provides data formats that enable progress without directly using original data—accelerating time to next steps.
As synthetic data shifts from “optional” to “essential infrastructure for AI,” organizations need safer, faster paths to data sharing, release, and AI training.
- How far can synthetic data generated from our organizational data be utilized?
- Can it be applied to public data release or inter-organizational collaboration?
- What validation evidence is needed for AI impact assessments or internal controls?
If you’re asking these questions, we can help map out application scenarios based on DTS capabilities. Reach out through the banner below—we’d love to hear from you. 😊

CUBIG's Service Line



Recommended Posts


