
Hello, this is CUBIG the company behind Syntitan, the AI-ready data platform for enterprise AI.
Ninety-five percent of enterprise AI adoption efforts returned no measurable profit last year, and the reason everyone repeats is the one MIT’s own data refuses to support.
Enterprise AI adoption is the work of turning a capable model into a result a business can book on its P&L, and most of it is stalling at exactly that step. In its State of AI in Business 2025 report, MIT’s NANDA initiative found that only about 5% of generative AI pilots reach real operational or financial impact. The other 95% spend the budget and move nothing on the books, a split the researchers named the GenAI Divide. Fortune put the spend behind that failure at $30 to $40 billion. The trend is moving the wrong way: in S&P Global Market Intelligence‘s 2025 survey, the share of companies that abandoned most of their AI initiatives climbed from 17% to 42% in a single year. The number is now quoted in every boardroom and most pitch decks. This piece reads it through one lens: what the 95% is actually being blamed on, what MIT’s data says instead, and why the gap between those two answers points at a problem nobody is selling a course for.
What the 95% number does to enterprise AI adoption
A failure number that large does not stay a research finding for long. It becomes a sales motion. Within weeks of the report, the dominant reading had settled into a single story: the pilots failed because the buyers were not ready. Not strategic enough, not mature enough, not transformed enough. The fix on offer is more transformation work and more strategy engagements. The 95% became a reason to hire the people who explain the 95%.
There is a second reading, popular among investors and operators, that the failure is organizational. Data sits trapped in departments, teams fight over ownership, and the AI never reaches the workflow it was bought for. That reading is closer to the ground, and it is partly right. But it tends to arrive with invented precision, a clean pie chart claiming some exact share is “politics” and some other share is “code.” The MIT report does not publish that split. Attaching it to MIT borrows authority the data does not give.
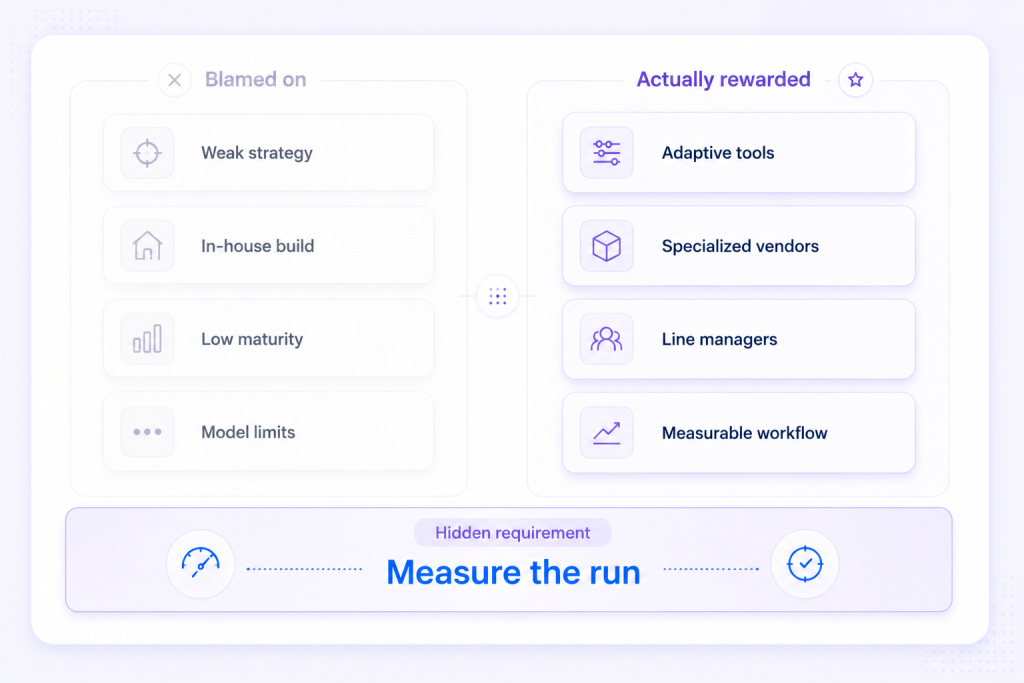
Read the report’s own findings and a different picture shows up. MIT points at a learning gap: tools that do not retain feedback or adapt to context cannot scale past the demo, no matter how strong the underlying model. The research also found that buying from specialized vendors and building partnerships succeeded roughly 67% of the time, while internal builds succeeded about a third as often. And the pilots that worked tended to be driven bottom-up by line managers, not handed down from a central AI lab. None of that is a strategy deficit. It is a question of whether the system adapts and whether anyone can see it working.
Every row on the right shares a hidden requirement. To reward an adaptive tool, you have to see it adapt. To prefer the vendor that worked, you have to know it worked. To credit the line manager’s deployment, you have to attribute the result to it. The whole of MIT’s success column rests on a capability the failure column never mentions: the ability to measure what a given AI run actually produced. That is where the more useful version of this conversation starts.
No measurable ROI is first a measurement problem
Strip the slogans and the 95% finding says something narrow and precise. These pilots produced no measurable return. Measurable is the load-bearing word. A pilot can move a real number and still land in the 95% if no one can prove the AI is what moved it. The same S&P Global survey found the average organization now scraps 46% of its AI proofs-of-concept before they reach production. A proof you cannot reproduce is a proof that does not survive the move from the demo to the floor.
Here is how that happens. The same model runs in the first quarter against one set of records and lifts a metric. It runs again in the second quarter against records that have quietly changed, and the lift is gone. Was that the model, the prompt, the team, or the fact that the input data was in a different condition the second time? With no way to reconstruct the state each run executed on, the question has no answer. And an answer is exactly what the next budget cycle demands. A result you cannot attribute is a result you cannot defend, and a result you cannot defend reads as a failure in the meeting that decides funding.
So a meaningful share of the 95% is AI that did something once and could not prove it twice. The precondition for measuring return on AI is the ability to reproduce the conditions a result was produced under. That sits underneath strategy, not after it. A flawless transformation program can still fail this test, because the test is about the data the model ran on, not the deck the consultants left behind.
Why most AI readiness is staged
The same blind spot runs through how readiness gets sold. Almost every AI readiness assessment is a claim made once. A team assembles the scorecard, presents it, the room nods, the project gets funded. Nothing in that ritual requires the state being described to still hold next month, or to have been reproducible when it was described. A one-time claim can be arranged for the day of the review. A claim arranged for one day is theater.
A better questionnaire does not fix this, because the problem is structural rather than a matter of rigor. Readiness has to become a property the system regenerates and checks on every run, instead of a figure asserted in a slide. When the data state behind a result has to reproduce each time the system executes, there is no scorecard to hide behind. The number stops being a story told once and starts being a fact the system can show on demand. This is the part of the current wave worth watching. A great many people are being trained to produce the assessment. Far fewer are being asked whether the thing assessed survives a second look.
The wall every pilot hits in production
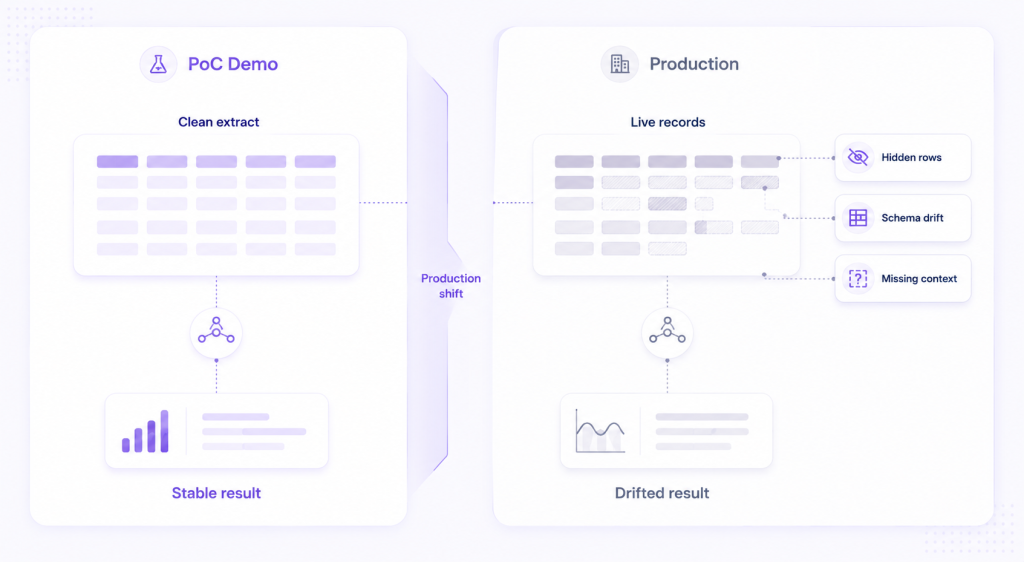
Sit with one project and the abstraction turns concrete. The proof-of-concept runs on a clean extract, the demo lands, the pilot is approved. Then the work moves into production and the ground shifts. The model now reads live records instead of the curated sample. Permissions hide rows the pilot could see. A column that was fully populated in March comes back half-null in June after an upstream system changed. Context that lived in one analyst’s head was never written down. Weeks later a result looks wrong, and no one can rebuild the exact data the model ran on to explain why.
Much of today’s engineering effort goes into controlling this with specs, gates, and evaluation loops. That is good discipline, and it catches one kind of drift, the kind that lives in code and process. It does not touch the other kind. Same pipeline, same prompts, next month’s data, and the output moves while nothing in the code changed. A model rarely breaks the way a test suite is built to catch. It passes the demo, reaches production, and drifts three weeks later when the data state under it is no longer the state it was validated against. Gartner has put a figure on the cost, expecting organizations to abandon 60% of AI projects through 2026 for lack of AI-ready data. In the same body of work, a 2024 Gartner survey of data management leaders found 63% of organizations either lacked the data practices AI needs or were unsure they had them. RAND, looking across the field, estimates that more than 80% of AI projects have historically failed to reach meaningful production. Data state is one driver of the GenAI Divide among several, including strategy and integration. It earns attention because it is the one that does not announce itself in the demo. We trace the mechanics in why AI fails after deployment.
Where this leaves CUBIG, and the teams running the pilots
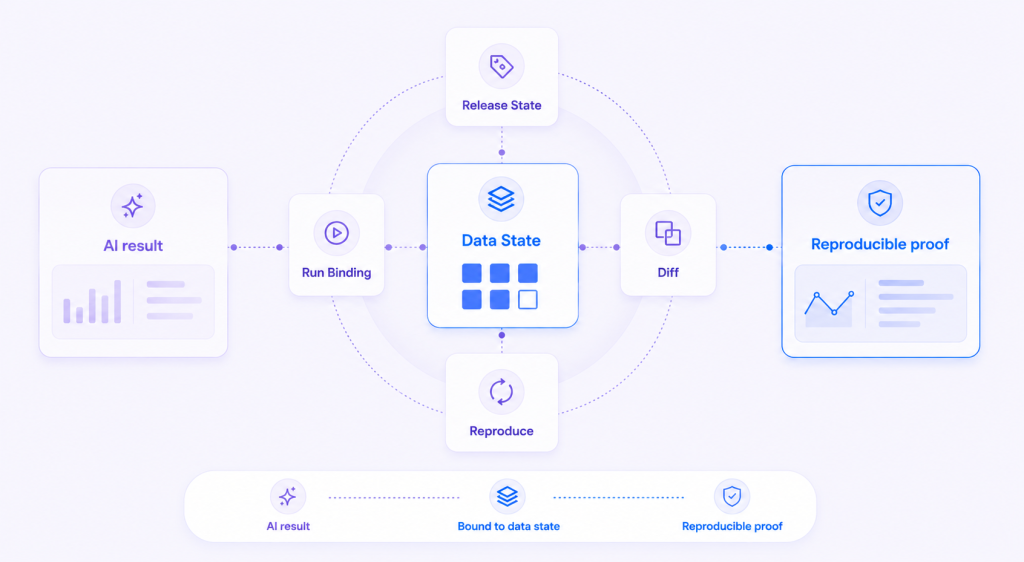
CUBIG does not sell strategy, and it does not replace the teams doing the deployment work. It removes the piece of that work that has to be rebuilt by hand on every engagement: confirming data is in a state AI can use, recording the exact data state a result came from, and reproducing it on demand. A few terms make the layer concrete:
- Data state. The condition of the data a model ran on, its contents, schema, permissions, and context at the moment a result was produced.
- Release State. A referenceable version of a data state, so a result is tied to the data it came from rather than to a memory of it.
- Run Binding. The link between a run, the model, and the data state it used, so an output can be reproduced instead of recalled.
- Diff and Reproduce. The ability to compare two data states and to re-run an earlier one, so a result is defended with evidence rather than a screenshot.
This is what AI-ready data means in practice. It is not tidy data. It is data in a state AI can use, that records how it was used, and that can be reproduced later. The 5% that cleared the GenAI Divide did not necessarily have better strategy than the 95%. They had results they could attribute and repeat, which is what let them defend the spend and earn the next round. As enterprise AI adoption scales, the teams that move from the 95% to the 5% will be the ones that stop reassembling data state by hand and start carrying it as infrastructure. Its platform, Syntitan, operates that layer through Release State, Run Binding, Diff, and Reproduce. Its transformation engine, DTS, rebuilds restricted or unusable data into an AI-ready state in the first place.
Before your next AI pilot
Five questions for anyone running or funding an AI pilot. The more of these that land on “no,” the more your real constraint is data state, the one no strategy engagement resolves on its own.
- Can you name the exact data state a given AI result was produced on?
- Would the same inputs, run again today, return the same output?
- When permissions or schema change, do your pilots survive the move to production?
- Could you defend a specific result to a CFO with evidence rather than a screenshot?
- Is data-readiness and proof rebuilt by hand each pilot, or carried as a reusable layer?
Try it on your data, free.
Run a sample proof and see your own data state, recorded and reproducible.
