
DTS is CUBIG’s AI-ready data transformation engine:
it rebuilds restricted, scarce, or structurally unusable enterprise data into data a model can learn on, while preserving the original’s structure, statistics, and rare patterns and never exposing the original itself.
It works in three moves: diagnose, transform, rebuild.
The word that matters in that sentence is transformation. DTS does not invent data, and it is not a synthetic-data generator. It starts from data you already own but cannot put in front of a model, and it rebuilds that data into a form the model can actually learn from. The source stays where it is. What comes back is new, usable, and faithful to the original’s shape.
The data you have, but can’t use
Most enterprises are not short on data. They are short on data a model is allowed to touch. Industry estimates put roughly 80% of enterprise data in the unstructured, rarely-used category, and much of that never reaches a model at all. The records exist. They sit in a system the training team is not permitted to draw from.
Three things usually stand between the data you have and the data a model can learn on.
The first is movement. The original cannot leave its environment for legal, contractual, or security reasons, so the team that needs it for training never receives a usable copy. The second is sensitivity. The records carry context you cannot expose, so they go untouched even by people cleared to see them, because routing them anywhere new carries a risk nobody wants to own. The third is scarcity, and teams tend to notice it last. The events a model most needs to recognize, such as fraud, equipment failure, or the rare clinical case, are exactly the ones that barely appear in the data. Train on what you have and the model learns the common case well and misses the case that matters.
None of this is a data-quality problem in the ordinary sense. The data is not dirty or wrong. It is simply not in a state a model can learn from, and cleaning it does not change that. That gap between raw records and a trainable dataset is what the data blockers describe.
| What blocks the data | Why a model can’t use it | What DTS does |
|---|---|---|
| It can’t move | The original can’t leave its environment | Reads the structure indirectly and rebuilds without moving the raw records |
| It’s too sensitive | Exposing the records crosses a legal or security line | Bounds re-identification with differential privacy; the original stays put |
| Rare patterns are missing | The events that matter barely appear | Amplifies those patterns from the real distribution |
Transformation, not generation
This is the line that separates DTS from a generator. A generator invents records from scratch. Generic or random rows can pass a human glance and still teach a model nothing, because they carry none of the relationships that made the original predictive. DTS keeps those relationships. It preserves the statistical structure, the correlations between fields, and the rare patterns that hold the most signal, so what you train on still behaves like the real thing. The output is rebuilt data. It is not fabricated, and it is not the original record either.
That distinction earns its keep in practice. Because the result is derived from your data rather than copied out of it, you can move it across teams or to partners within limits the source records could never clear. And because it tracks the original’s structure, a model trained on the rebuild performs close to one trained on the source.
That principle is well established. In MIT’s Synthetic Data Vault study, models built on data that preserved the correlations between fields matched or outperformed models built on the original in more than 70% of cases. DTS applies the same structure-preserving idea to the data you already hold, instead of generating new records from nothing.
Diagnose, transform, rebuild
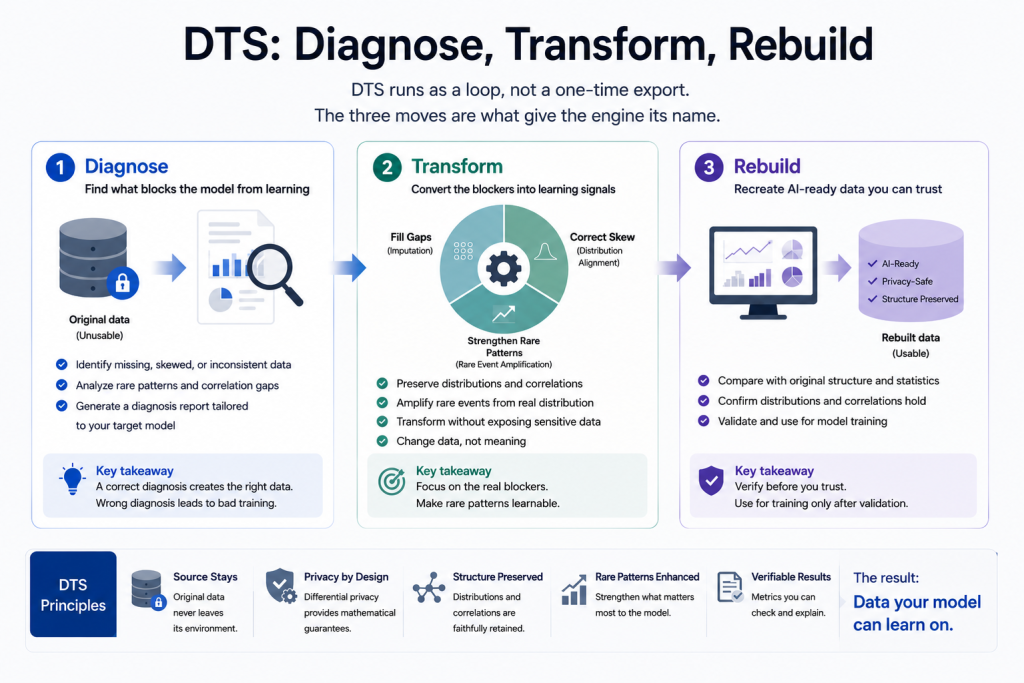
DTS runs as a loop, not a one-time export. The three moves are what give the engine its name.
Diagnose. Before changing anything, the engine reads what makes the data unusable for your specific target model: what is missing, what is skewed, which patterns are too thin to learn from, and where the sensitivity sits. A rebuild aimed at the wrong problem produces data that looks fine and trains badly, so the diagnosis comes first.
Transform. Next it works on the parts that block learning. It fills the gaps, corrects the skew, and strengthens the rare patterns a model needs more examples of. Scarcity gets solved here: the rare event is amplified from the real distribution, not conjured out of nothing.
Rebuild. The output is an AI-ready dataset you can check against the original’s structure and statistics before you trust it. You are not asked to take the result on faith. You compare distributions, confirm the correlations held, and only then train.
Is your data AI-ready? A quick diagnosis
Before any rebuild, it helps to know which blocker you are dealing with. Five questions usually settle it:
- Movement. Can a copy of this data legally leave the environment it lives in?
- Sensitivity. Could the records go to an external model without crossing a legal or contractual line?
- Scarcity. Do the rare events you need the model to catch appear often enough to learn from?
- Quality. Are gaps, skew, or imbalance likely to bias what the model learns?
- Shareability. Can the result be shared across teams or partners under your regulations?
A “no” to any of these means the data is not yet in a s
How AI-ready data transformation works
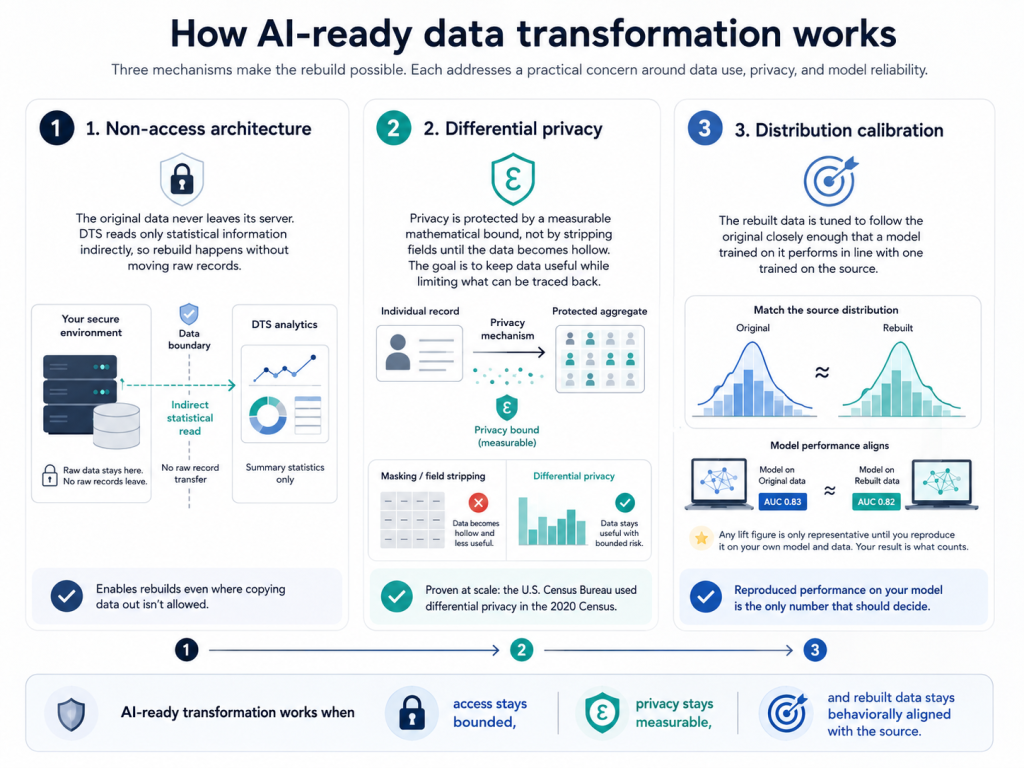
Three mechanisms make the rebuild possible. Each one answers a specific objection a security or compliance reviewer will raise, which is why they are worth stating plainly.
The first is a non-access architecture. The original never leaves its server. DTS reads only statistical information, and reads it indirectly, so the rebuild happens without the raw records moving anywhere. That is what lets the work begin at all in environments where copying data out is the one thing nobody will approve. The same principle, applied to running a model rather than rebuilding data, is the restorable AI data boundary.
The second is differential privacy. Re-identification of any individual record is held to a measurable mathematical bound, rather than controlled by deleting fields until the data is hollow. Masking makes data safe by making it poorer. Differential privacy keeps the data useful while putting a provable limit on what can be traced back. The approach is proven at scale: the U.S. Census Bureau adopted differential privacy to protect respondents in the 2020 Census.
The third is distribution calibration. The rebuilt data is tuned to follow the original closely enough that a model trained on it performs in line with one trained on the source. Any lift figure you see is representative until you reproduce it on your own model and your own data, and that reproduced number is the only one that should decide anything.
Where DTS fits
Once data is rebuilt, the work that used to be off-limits becomes routine. You train and fine-tune on data that was locked. You evaluate and test without touching the original. You share results across teams or with partners inside regulatory limits, because what you are sharing is no longer the source record.
DTS is the step that moves data from “managed” to genuinely AI-ready data. It pairs with sensitive AI workflow enablement, which clears the confidential-context problem so a workflow can run in the first place. DTS takes the harder case, where the data is not only sensitive but scarce or structurally unusable. Both are capabilities of the CUBIG Syntitan platform, so the transformation engine and the enablement layer share one boundary instead of bolting two tools together.
Related: What is Sensitive AI Workflow Enablement? · What is AI-Ready Data? · Syntitan
