Hello, this is CUBIG, an AI-ready data infrastructure company💎.
We turn enterprise data into a state AI can use, run repeatedly, and trace in production.
Model collapse is the progressive degradation of an AI model trained on contaminated or low-quality data, including data generated by other models.
The learned distribution narrows, outputs get worse, and those outputs feed the next round of training.
In production pipelines, the most common cause is an entrance with no quality gate: nothing checks distributions, missing-value rates, or schema before data reaches training.
The question has moved out of research papers and into user forums. On r/GeminiFeedback, someone asked whether model collapse is already happening with Gemini, and most replies agreed the outputs feel worse.
A thread on r/accelerate collected more than sixty comments arguing that AI-generated feedback loops degrade quality fast and that uncontaminated training data is finite.
On r/science, a discussion of the Nature paper that formalized the phenomenon passed 260 comments. People are noticing, and most of them are blaming the wrong layer.
How model collapse happens
The Nature paper by Shumailov and colleagues gave the phenomenon a formal description in 2024: models trained on recursively generated data lose the tails of the original distribution first.
Rare patterns disappear, then variance shrinks, and each generation learns from a slightly narrower picture of the world than the one before it. The decay is hard to see in any single batch and obvious across a quarter.
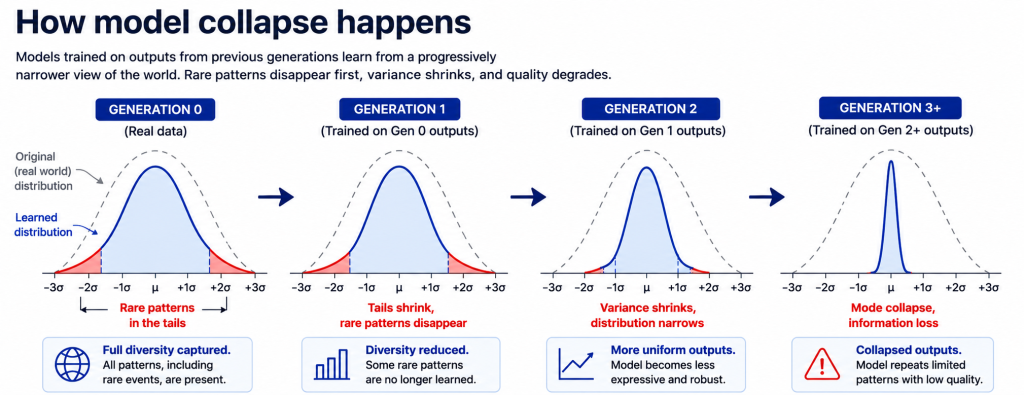
Across generations the learned distribution narrows: tails go first, variance shrinks, then the model collapses to a single mode.
(Mechanism based on Shumailov et al., Nature 2024.)
The loop closes when degraded outputs get scraped, distilled, or pasted back into training corpora.
Nothing in that loop requires synthetic data, and any low-quality source that enters training unchecked produces the same arithmetic.
The synthetic data framing doesn’t hold
The reflex in those threads is to blame synthetic data, and the instinct is understandable. Model-generated text feeding model training sounds like the definition of the problem.
The numbers say otherwise. A widely shared analysis on Hacker News estimated that roughly 70 percent of current training data is already synthetic or distilled. If synthetic data were inherently toxic, every frontier lab would be watching its models fall apart right now.
They are not, because the labs that operate at that share of synthetic data run heavy filtering and validation on everything that enters training.
The axis that decides outcomes is not synthetic versus real. It is checked versus unchecked.
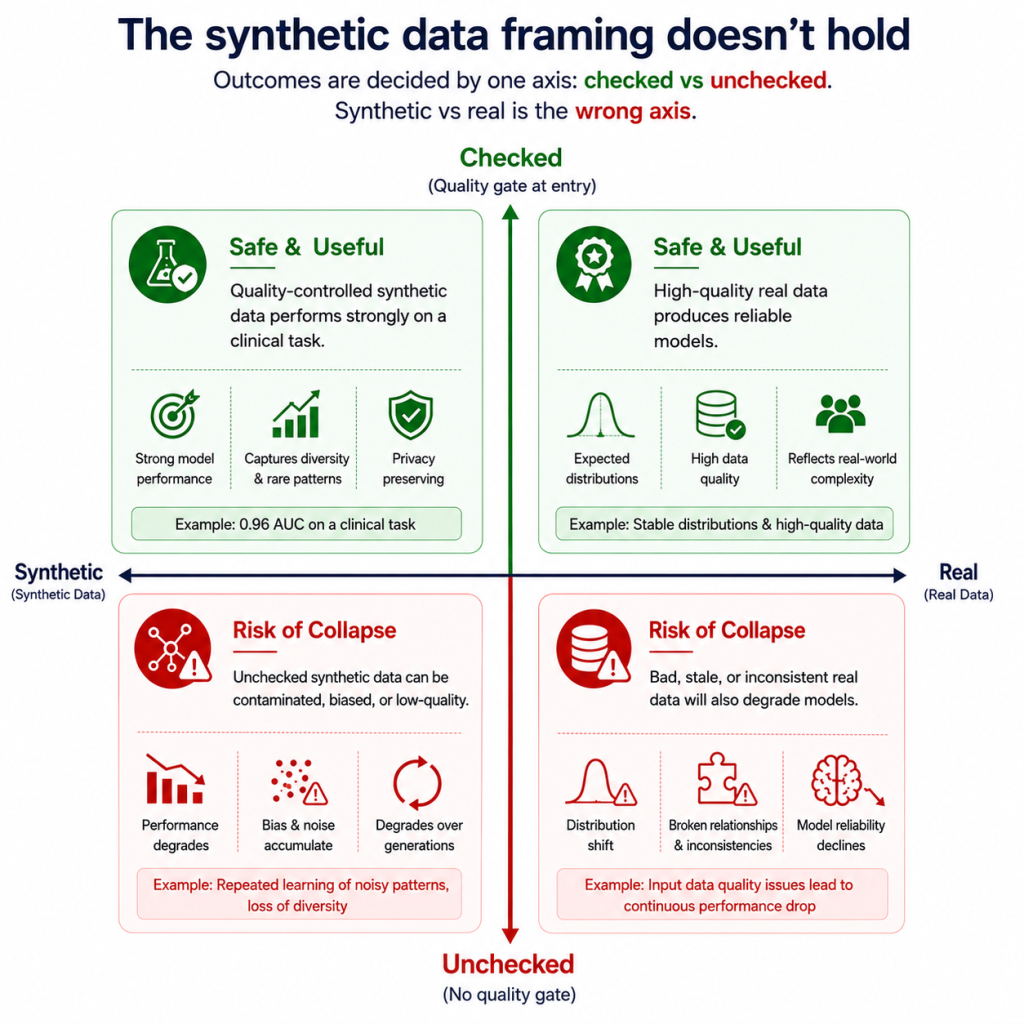
The deciding axis isn’t synthetic versus real, but whether data is checked at ingestion.
Clinical example based on synthetic-data results in Nature’s Scientific Reports.
The real model collapse cause: no quality gate at the entrance
Most pipelines have no front door.
Data arrives from external APIs, vendor feeds, scrapes, and internal systems. In most training setups, nothing asks whether the distribution of an incoming batch sits in expected ranges, whether the share of missing values jumped, whether the schema matches what the trainer expects, or whether relationships between variables still look plausible. Whatever arrives is whatever trains. An LLM-written corpus slips into a scrape and no one flags it, because data contamination detection is not a standard stage in most training pipelines. It is an incident review finding.
Here is what that looks like from inside a team. Monday morning, a Slack alert: accuracy down 1.2 percent. Hyperparameters untouched. Pipeline unchanged. Three hours of digging later, the cause surfaces: an external API changed its output format, the schema no longer matched, and with no validation at ingestion the malformed batch went straight into training. Anyone who has run a production model has a story like this, and rarely just one. In Anaconda’s State of Data Science survey, data scientists reported spending close to 45 percent of their time getting data ready before any modeling starts.
A lot of that time is this: cleaning up after data that should have been stopped at the entrance.
What the evidence shows
The medical-AI field has tested this directly, because synthetic patient data is one of the few ways to train models without touching real records. In a study published in Nature’s Scientific Reports, models trained on synthetic Synthea patient records reached an AUC of 0.96 on a clinical risk-prediction task strong performance from data containing no real patients.
The collapse Shumailov and colleagues documented came from a different condition entirely: model-generated content fed back into training with nothing filtering it. Same raw ingredient, two outcomes, and what separated them was the controls applied on the way in.
That should redirect the debate. Teams arguing synthetic-versus-real are measuring a variable that does not decide much, while AI training data quality at the point of ingestion, the one that does, goes unmeasured.
What a data quality validation pipeline checks
A quality gate is four checks that run automatically, on every batch, before training:
- Schema enforcement. The trainer expects 12 columns and gets 11: block the batch and page someone. Don’t let the model discover the difference.
- Missing-value thresholds. A null rate that moves from 2 percent to 15 percent is upstream breakage. Catching it at the gate costs minutes; catching it after a training run costs days.
- Distribution validation. Compare incoming batches against expected ranges. A KS test is enough to start. Flag shifts before they become training data.
- Correlation sanity checks. When variables that have always moved together stop doing so, something upstream changed, and the model should not be the first to find out.
None of this is exotic. The checks run in seconds, the thresholds come from data you already have, and the tooling matters far less than the decision to run checks at all. Quarantine suspicious batches rather than silently dropping them, make failures loud, and the gate pays for itself the first time it fires.
The cost of staying unchecked
Gartner predicts that through 2026, organizations will abandon 60 percent of AI projects unsupported by AI-ready data. That figure tends to get read as a procurement problem, something to solve with a bigger platform. Read it operationally instead: most of those projects trained on whatever showed up, and the gap between a pilot that demos well and a system that survives production is often a quality gate that was never built.
For teams heading toward AI-ready data, the ingestion gate is the first and cheapest piece. It is also the difference between catching contamination on arrival and spending a quarter explaining degraded outputs after the fact
