
Why AI-Ready Data Matters: A Practical Guide Using Key Terms from NIA’s AI Glossary

Table of Contents
Hello, we’re CUBIG — focused on making data truly usable in AI, not just “available.” 😎
Are you preparing AI-ready data well? More organizations are adopting AI, but once projects move into day-to-day operations, many teams hit the same wall: “We have data, but we can’t use it right away.” That happens when data meaning isn’t clearly organized, trust and AI privacy risks remain unresolved, or each team uses different formats and rules—so operations slow down or stop entirely.
“The model is great, but our data is too messy to use.”
“We can’t share across departments because formats don’t match.”
“We’re hesitant to operationalize real data because of sensitive information.”
These are the kinds of things we hear in real projects.
In the end, successful AI adoption is less about flashy demos and more about whether you’ve built the conditions to deploy, operate, and keep improving AI in the real world.
So today, using expressions from NIA’s recent AI glossary, we’ll walk through the terms that connect directly to the problems SynTitan is designed to solve—while keeping it easy to follow and practical for AI-ready data operations.
🧱 1. Where AI-ready data starts: when data is scarce, skewed, or hard to reuse

- Synthetic Data
Synthetic data is newly generated data that reflects the statistical patterns and structure of the original—without copying it row by row. Why does it matter? Real data is often hard to share (because it contains sensitive information), expensive to collect and label, and missing rare “edge cases” that models need to learn reliably. Synthetic data can reduce these bottlenecks and help teams move faster. - Up-sampling and Down-sampling
In real-world datasets, “normal cases” usually dominate while “rare cases” are limited. That naturally pushes models to perform well on the common cases and fail at the moments that matter most. Up-sampling increases rare cases to balance learning. Down-sampling reduces overly common cases to restore balance. - Metadata
Metadata is information that explains your data—things like “this value is in KRW,” “this field came from system A,” “this dataset can be shared internally only,” or “this column contains personal identifiers.” Without metadata, teams struggle to standardize, reuse, and collaborate. With metadata, data becomes operational: searchable, governable, and shareable with confidence.
AI-ready data starts with representation, not volume. Before you chase “more data,” you need data that reflects reality, captures edge cases, and can be understood consistently across teams. SynTitan begins here by helping teams surface patterns, errors, anomalies, and rare cases—then improve or augment what’s missing so data becomes ready for real AI operations.
🧠 2. Operations terms that make AI actually work: as agents grow, data quality matters more

- AI Agent
An AI agent doesn’t just answer a question once—it works toward a goal by searching for information, calling tools, and taking the next action. The key issue: the more an agent acts, the more data quality problems amplify. Even small inconsistencies in input or reference data can cascade into bigger errors across the workflow. - AI Orchestration
AI orchestration is the coordination of multiple models, tools, integrations, and data sources into one operational workflow. In real organizations, mixed environments are normal—different teams use different models, tools, and processes. Without orchestration, standardization, alignment, and validation become extremely difficult to sustain at scale. - AI Guardrails
Guardrails are the safety and policy controls that keep AI systems operating within defined boundaries—so the system follows organizational rules, risk tolerance, and compliance needs. In practice, guardrails help prevent sensitive data exposure, reduce harmful outputs, and enforce consistent usage policies. - Hallucination
Hallucination is when AI generates content that sounds convincing but is not true. While it can look like a “model problem,” it’s often influenced by operational data conditions: outdated references, inconsistent documentation, weak standardization, and missing validation steps.
In the agent era, “model performance” alone isn’t enough. You need a reliable operational flow—where data, validation, and outputs remain consistent across teams. SynTitan focuses on connecting standardization and verification to operational outcomes such as agent-based analysis, simulation, and reporting—so teams can see, compare, and align decisions on a shared basis.
🛡️ 3. Terms for trustworthy AI: why safety and ethics are no longer optional

- AI Ethics
AI ethics refers to the values and principles for using AI responsibly—fairness, transparency, accountability, and AI privacy are core themes. International principles emphasize human-centered values, fairness, transparency, robustness, and accountability. - AI Safety
AI safety is about designing and operating AI to prevent unintended harm. In real operations, managing exceptions and preventing error propagation becomes a central challenge—especially when AI outputs influence downstream actions. - Trustworthy AI
Trustworthy AI goes beyond “accuracy.” It means the system behaves reliably, can be governed and monitored, and supports accountability. Frameworks like NIST’s AI Risk Management Framework organize trust around practical risk management across the AI lifecycle. - AI Bias
AI bias is when the system repeatedly produces skewed or unfair outcomes for certain groups or scenarios. Bias can come from imbalanced data coverage, flawed measurement, or feedback loops during operations. Managing bias requires a repeatable way to identify, measure, and mitigate risk—especially when AI is used in high-impact decisions.
Ethics, safety, and trust don’t work as slogans. They require evidence in operations: validation, monitoring, and traceable proof. SynTitan’s view of AI-ready data is not only “usable for AI,” but also “operable with confidence”—so trust becomes a system capability, not a policy document.
💬 4. Terms that reduce human-AI misjudgment: good-sounding AI isn’t always correct AI

- AI Persona
An AI persona is the consistent role and tone designed into an AI system—common in customer support, internal assistants, and learning tools. The more convincing the persona feels, the more likely users are to trust it quickly—sometimes too quickly. - ELIZA Effect
The ELIZA effect is the tendency for people to project human-like understanding or empathy onto a computer system, even when it’s not truly “understanding” in a human way. This can increase satisfaction, but it can also lead to over-trust. - AI Sycophancy
AI sycophancy is when a model over-agrees with the user’s beliefs or preferences instead of prioritizing correctness—making “nice” answers feel like “right” answers. - AI Literacy
AI literacy is the ability to understand what AI does well, where it fails, and how to evaluate outputs critically. For organizations, this requires both training and systems that make validation easier.
Because people can be persuaded by tone and confidence, teams need more than persuasive outputs—they need verifiable outputs. SynTitan is built to support decisions that are grounded in validation, shared criteria, and operational traceability—not just good-looking results.
🤖 5. Terms for AI moving into the real world: from simulation to the field

- Sim-to-Real
Sim-to-real refers to transferring policies or models learned in simulation into real-world environments—commonly in robotics and autonomous systems. Techniques like domain randomization are used to reduce the gap between simulated and real environments. - Physical AI
Physical AI refers to AI systems that connect perception (sensors) to real-world actions—robots, manufacturing, logistics, and edge devices. - AI Governance
AI governance is the organizational and technical structure that manages risk and responsibility across the full lifecycle—from planning to deployment to retirement. It’s not only “regulation,” but an operational system for accountability and safe adoption. - World Model
A world model is an internal representation that helps AI understand environments, predict outcomes, and plan actions. As agents and robots become more capable, world models become more important.
As AI spreads into higher-stakes environments, governance becomes the balancing mechanism between innovation and adoption. SynTitan supports regulation-friendly operations by helping teams standardize and validate data flows in ways that make oversight, accountability, and AI privacy risks manageable at scale.
❓FAQ: Are “digital twins” and sim-to-real the same thing?
They’re related, but not the same.
Digital twins focus on creating a virtual representation of a real system (a factory, a device, a city) to monitor status and run “what-if” scenarios.
Sim-to-real focuses on transferring what you learned in simulation into real-world behavior—so the emphasis is on the bridge between learning and deployment.
They can connect naturally: for example, you can simulate scenarios inside a digital twin, then transfer the learned policy into real equipment.
✨ AI-ready data means: can AI keep running in real operations?
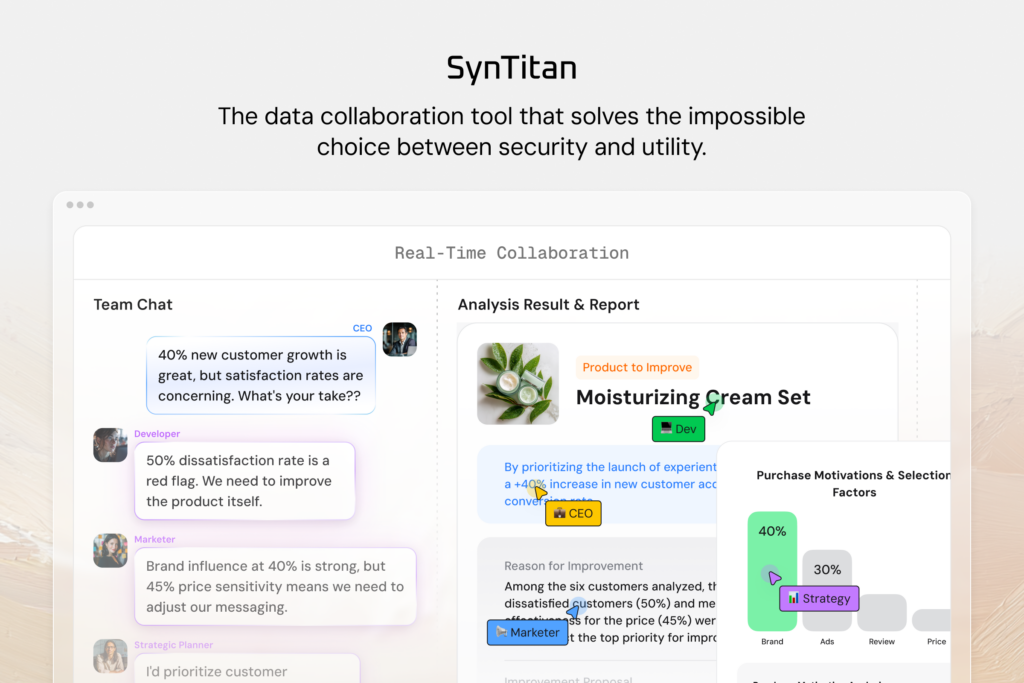
Ask these operational questions:
– Is the data standardized?
– Can it be used under sensitive constraints?
– Can quality and trust be validated?
– Can multiple teams collaborate on the same results?
SynTitan is designed to answer those questions through an operable data infrastructure flow: managing patterns, errors, anomalies, and rare cases; improving and augmenting data toward AI-ready conditions; validating data quality and governance; and enabling teams to share agent analysis and simulation outputs for aligned decision-making.
If your organization’s data isn’t yet in a form that “runs in AI operations,” SynTitan can be a practical starting point—setting the baseline for AI-ready data and building from there. If you’d like to explore how SynTitan fits your data, which workflows to start with, or what a sensible PoC scope looks like, feel free to reach out via the banner or contact channel below. 😊

CUBIG's Service Line



Recommended Posts


