Why Enterprise AI Stalls: From Big Data to AI-Ready Data

Table of Contents
Almost every organisation today claims to be pursuing AI transformation.
AI appears prominently in strategy documents, and PoCs and pilot projects continue to emerge across teams.
Yet in practice, it remains rare to see AI materially change how decisions are made.
For more than a decade, enterprises treated Big Data as a strategic asset.
Collecting more data, storing it longer, and securing it more tightly became synonymous with competitiveness.
As data warehouses expanded, a widely held assumption took root: data was no longer the constraint.
As AI adoption accelerates, that assumption is increasingly being challenged.
Across industries, many enterprise AI projects fail to reach their expected return on investment.
A significant number stall at the PoC stage or require repeated course correction.
While reported figures vary, the underlying pattern is consistent.
Enterprise AI initiatives tend to stall for structural reasons, not technical ones.
This leaves a fundamental question.
If data is abundant, why does AI struggle to deliver impact?
The Data AI Requires Is Not the Data Enterprises Collected

The explanation is straightforward.
Most enterprise data was collected to serve human decision-making—
reporting, operational reviews, and audit requirements.
AI, by contrast, depends on data designed for machine learning.
The conditions that make data suitable for reports are fundamentally different from those required for pattern learning and prediction.
AI does not consume summaries or dashboards.
It learns by identifying patterns, distinguishing exceptions, and modelling possible futures.
To function effectively, AI requires:
- Not only common cases, but also rare and exceptional events
- Context connected across fragmented systems
- Data that can be accessed and validated without being immobilised for months by legal or security constraints
When these conditions are not met, data no longer functions as an asset.
From an AI perspective, it often becomes a cost centre that generates maintenance overhead without enabling action.
As a result, the basis of data competitiveness is shifting
from volume to readiness.
AI-Ready Data: Beyond “Clean” Data

AI-Ready Data is often misunderstood as clean or well-organised data.
Correcting spreadsheet errors or filling missing values may improve readability for humans,
but it does not make data suitable for AI.
Human-readable data and machine-learnable data follow different standards.
AI-Ready Data refers to data that has been intentionally engineered to be used immediately across the AI lifecycle from training and tuning to evaluation.
This requires deliberate design choices regarding:
- How data is collected
- How it is distributed
- How it is structured
- Under what conditions it can be used
AI-Ready Data can be defined by three core requirements.
1. Representativeness
Models trained only on typical patterns struggle to recognise abnormal situations.
In many business contexts such as fraud detection, equipment failure, or customer churn—the most consequential events are also the rarest.
AI-Ready Data must statistically reflect reality, including edge cases that are underrepresented in raw datasets.
2. Machine-Readable Quality
Model performance depends on more than surface-level cleanliness.
Consistency in labelling, preserved relationships between variables, and stable data distributions directly influence learning outcomes.
The objective is not interpretability for humans, but reliability and learnability for algorithms.
3. Compliance
Even high-quality data cannot be considered AI-Ready if legal or security constraints prevent its use.
AI-Ready Data must remain usable under regulatory environments such as data protection laws, GDPR, and the EU AI Act, without prolonged delays or operational bottlenecks.
Stored Data and Working Data Are Not the Same
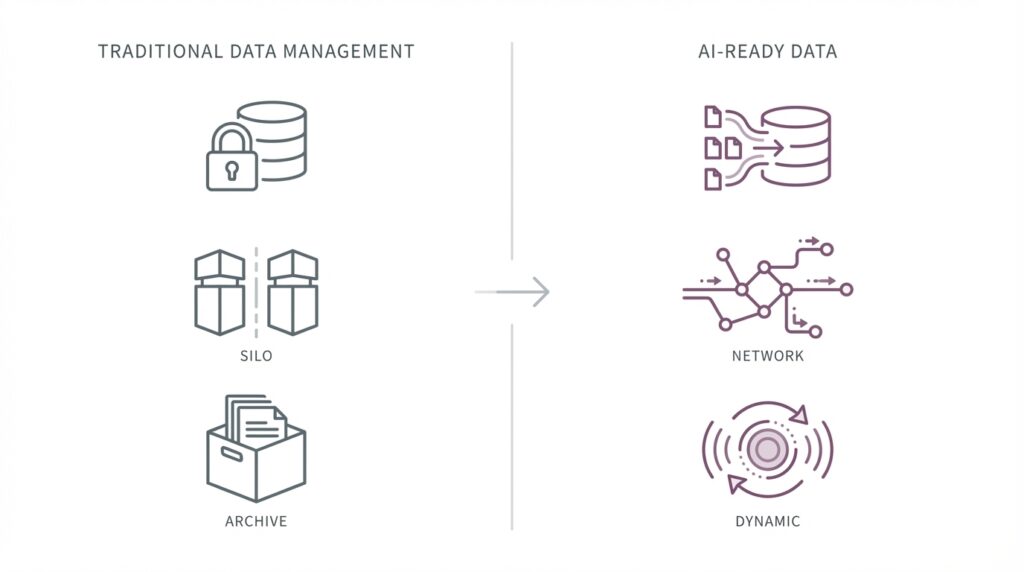
Traditional data management systems are designed to explain the past.
Data is stored securely, access is tightly controlled, and analysis is performed retrospectively—
a model well suited to BI and reporting environments.
AI operates under a different logic.
It must traverse data boundaries, connect context, and explore multiple assumptions in parallel.
When data is not prepared for this mode of operation, data lakes gradually turn into data swamps complex, costly, and difficult to use.
AI-Ready Data is not designed to be stored. It is designed to operate.
Rather than accumulating more data, the focus shifts to preparing data that can be immediately deployed for experimentation, learning, and simulation.
Comparison: Traditional Data Management vs. AI-Ready Data
| Category | Traditional Data Management | AI-Ready Data |
|---|---|---|
| Primary Purpose | Explaining the past | Predicting the future |
| Data State | Locked, fragmented | Usable, dynamic |
| Processing Approach | Aggregation and summarisation | Preservation of raw patterns and diversity |
| Security & Access | Access control (restricted by default) | Synthetic data (safe and usable) |
Why Data Stops Moving: Data Unusability

According to industry research, 80–90% of enterprise data exists in unstructured form, and more than 90% of organisations utilise only a small fraction—often less than 10%—of the data they possess.
Limitations in data collection, regulatory and security constraints, and quality issues prevent most enterprise data from being used in practice.
At CUBIG, we describe this condition as Data Unusability.
Data Unusability does not refer to a single technical flaw.
It emerges when data cannot be used at the moment it is needed, even though it exists.
In enterprise environments, this typically appears in three forms.
1. Uncollectable Data
Events with the highest business impact—such as financial fraud, industrial equipment failure, or rare diseases—occur infrequently by nature.
As a result, real-world data for these cases is extremely sparse.
Even when organisations operate at scale, these events do not generate enough examples to support reliable model training.
2. Locked or Restricted Data
The most valuable datasets—customer information, medical records, financial transactions—are also the most tightly regulated.
Regulatory requirements, network segmentation, and internal security policies often prevent these datasets from being accessed by AI models at all.
In many cases, data exists but is effectively unreachable.
3. Broken or Low-Quality Data
Missing values, bias, inconsistent formats, and fragmented schemas directly undermine model performance.
These issues do not merely reduce accuracy—they can lead to misleading outputs and incorrect decisions.
Importantly, Data Unusability is not a problem of individual teams or skills.
It is a structural problem rooted in how data is governed, prepared, and made available across the organisation.
SynTitan: A New Standard for AI-Ready Data Infrastructure
SynTitan is an AI Decision OS designed to move data from an unusable state to one that actively supports decision-making.
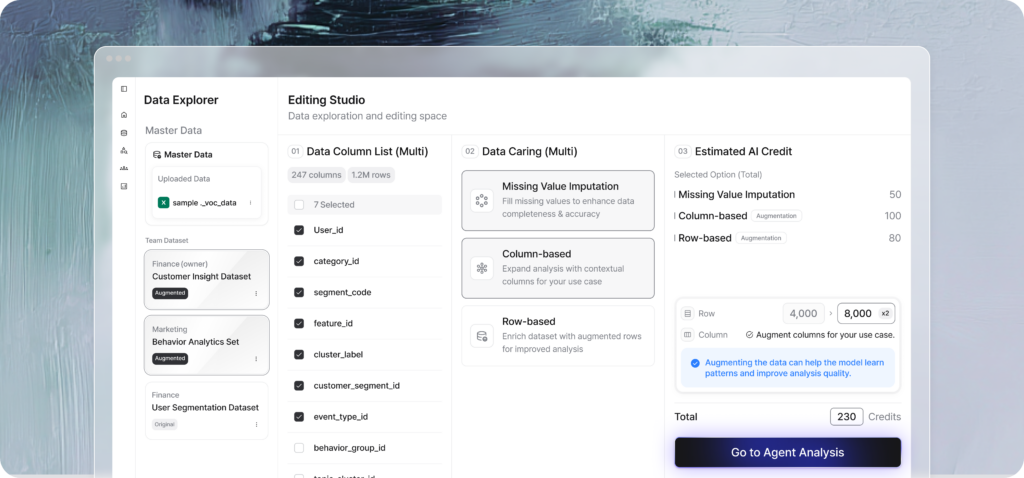
From the moment data enters SynTitan, the system evaluates what is actually possible with that data.
Issues such as missing values, distribution imbalance, sensitive attributes, and data quality are diagnosed before analysis begins, clearly defining the boundaries of usability.
Rather than relying on raw data, SynTitan adopts a synthetic-first architecture.
This enables analysis and experimentation even under strict regulatory and security constraints, without exposing original data.
SynTitan does not treat analysis as an endpoint.
On prepared data, teams can compare alternative business scenarios and simulate the outcomes of different choices. The system supports decision-making itself, not just reporting.
Data does not remain static.
It moves forward into action.
AI succeeds not in organisations that simply possess large volumes of data,
but in those that have built data structures that can actually be used.
If you are exploring AI adoption approaches tailored to your organisation—
and use cases that reflect the realities of your data environment—
SynTitan provides a practical starting point.

CUBIG's Service Line



Recommended Posts


