- 컨설턴트가 “AI-Ready”를 정의합니다
- 6개월짜리 준비 프로젝트
- 끝없이 반복되는 PoC
- 에이전트가 데이터에서 멈춥니다
- “되기를 바랍니다”
Syntitan · 재현 가능한 AI-Ready 데이터 플랫폼
데모 성공이
데모 성공이
운영 성공은 아닙니다.
내 데이터로 성능을 직접 증명하세요.
문제는 모델이 아니라 데이터입니다. Syntitan은 데이터를 AI-ready 상태로 만든 뒤, 운영에 들어가기 전에 성능이 얼마나 오르는지 증명합니다.
가입 즉시 무료 체험. 영업 미팅도, PoC도 없습니다.
기존 vs 신규
AI-Ready로 만드는 데 매달리지 마세요.
AI-Ready로 만드는 데 매달리지 마세요.
처음부터 AI-Ready로 시작하세요.
컨설턴트도, 준비도 워크숍도, 감으로 하는 점검도 없습니다. 가입하고 바로 실행하세요.
- 영업 미팅 없이 가입
- 30초 만에 6축 준비도 점수
- PoC가 아니라 작동하는 제품
- 같은 데이터에서 에이전트가 더 정확해집니다
- 결과를 그대로 직접 재현합니다
검증 가능한 데이터 상태
AI는 모델에서 망가지지 않습니다.
AI는 모델에서 망가지지 않습니다.
데이터 상태에서 망가집니다.
어제 작동하던 실행이 오늘 망가지는데, 무엇이 바뀌었는지 아무도 짚지 못합니다. Syntitan은 모든 AI 실행 뒤의 데이터 상태, 즉 그 결과가 정확히 어떤 버전의 데이터에서 나왔는지를 관리합니다. 그리고 그 상태가 실제 모델 성능과 어떻게 이어지는지 직접 검증하게 해줍니다.
릴리스 상태 (Release State)
AI가 사용한 정확한 데이터 상태를 고정합니다. “3월에 무슨 데이터로 학습했지?”가 감사 때 클릭 한 번으로 답이 됩니다.
실행 연결 (Run Binding)
모든 AI 실행이 데이터 상태에 연결되어, “이 결과는 바로 이 데이터에서 나왔다”가 자동으로 추적됩니다.
변경 비교 (Diff)
어제와 오늘의 데이터를 비교합니다. 출력이 흔들릴 때, 데이터가 바뀌었는지 몇 초 만에 확인합니다.
재현 (Reproduce)
과거 상태를 복원해 다시 실행합니다. “3월엔 됐는데 4월엔 깨졌다”를 추측하지 않고 그대로 재현해 조사합니다.
AI-ready
AI-ready는 한 가지가 아니라,
AI-ready는 한 가지가 아니라,
측정 가능한 6가지 축입니다.
보유한 데이터에서 AI가 실제로 돌아가는지,
무엇부터 고쳐야 하는지 여섯 가지 기준으로 확인합니다.
활용성 (Usability)
민감 데이터를 AI에 안전하게 쓸 수 있는가?
대표성 · 보강(enrichment) · 정량화
무결성 (Integrity)
결측치·중복·왜곡이 보이는가?
데이터 품질 · 편향 · 정확성
맥락 (Context)
각 필드가 무엇을 의미하는지 AI가 알 수 있는가?
의미(시맨틱스) · 추론과 파생
일관성 (Consistency)
어떤 필드가 AI 작업에 도움이 되거나 해가 되는가?
일관성 평가 · 기록 통일
재현성 (Reproducibility)
이 데이터 상태를 워크플로우에서 재사용할 수 있는가?
버전 관리 · 검증 · 회귀 테스트
추적성 (Traceability)
변경·버전·작성자를 추적할 수 있는가?
리니지(계보) · 스튜어드십 · 컴플라이언스
Gartner, AI-Ready Data Essentials Roadmap (2024) · Map Your AI Use Cases by Opportunity (2025)
제품
데이터 진단부터 검증된 증명까지.
데이터 진단부터 검증된 증명까지.
하나의 워크스페이스.
데이터 진단부터 모델 검증까지, 실제 Syntitan 제품을 둘러보세요.
단계를 선택하면 해당 워크스페이스가 열립니다.
AI 준비도 진단
데이터가 AI에 쓸 준비가 됐는지 6축으로 진단하고, 무엇부터 고칠지 짚어냅니다.
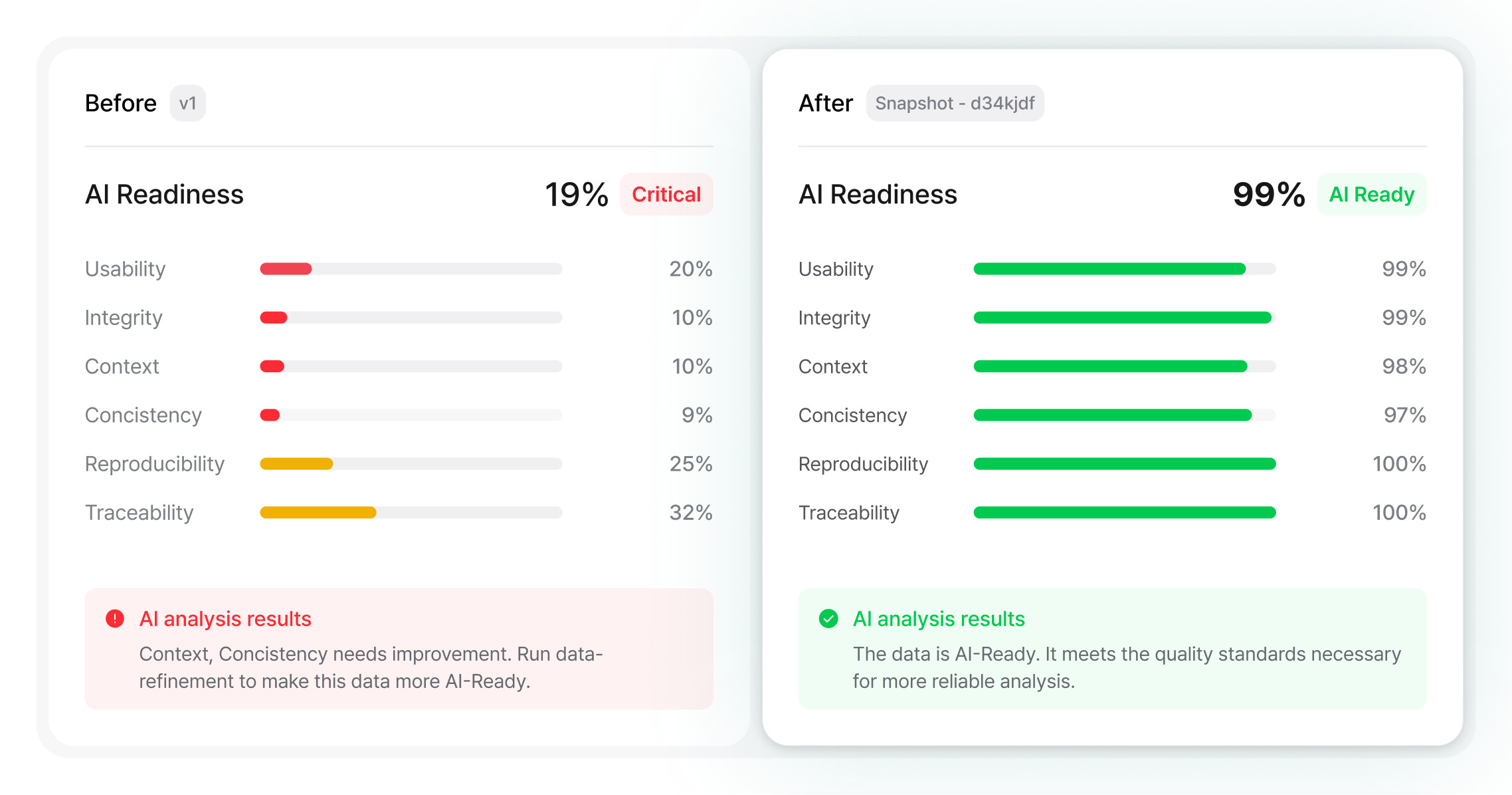
전체 AI 준비도
61%주의
AI 분석 결과
AI 준비도가 부분적입니다. Integrity(34%)와 Context(30%)가 위험할 만큼 낮습니다. 학습 전에 먼저 해결하세요. 나머지 네 축은 통과입니다.
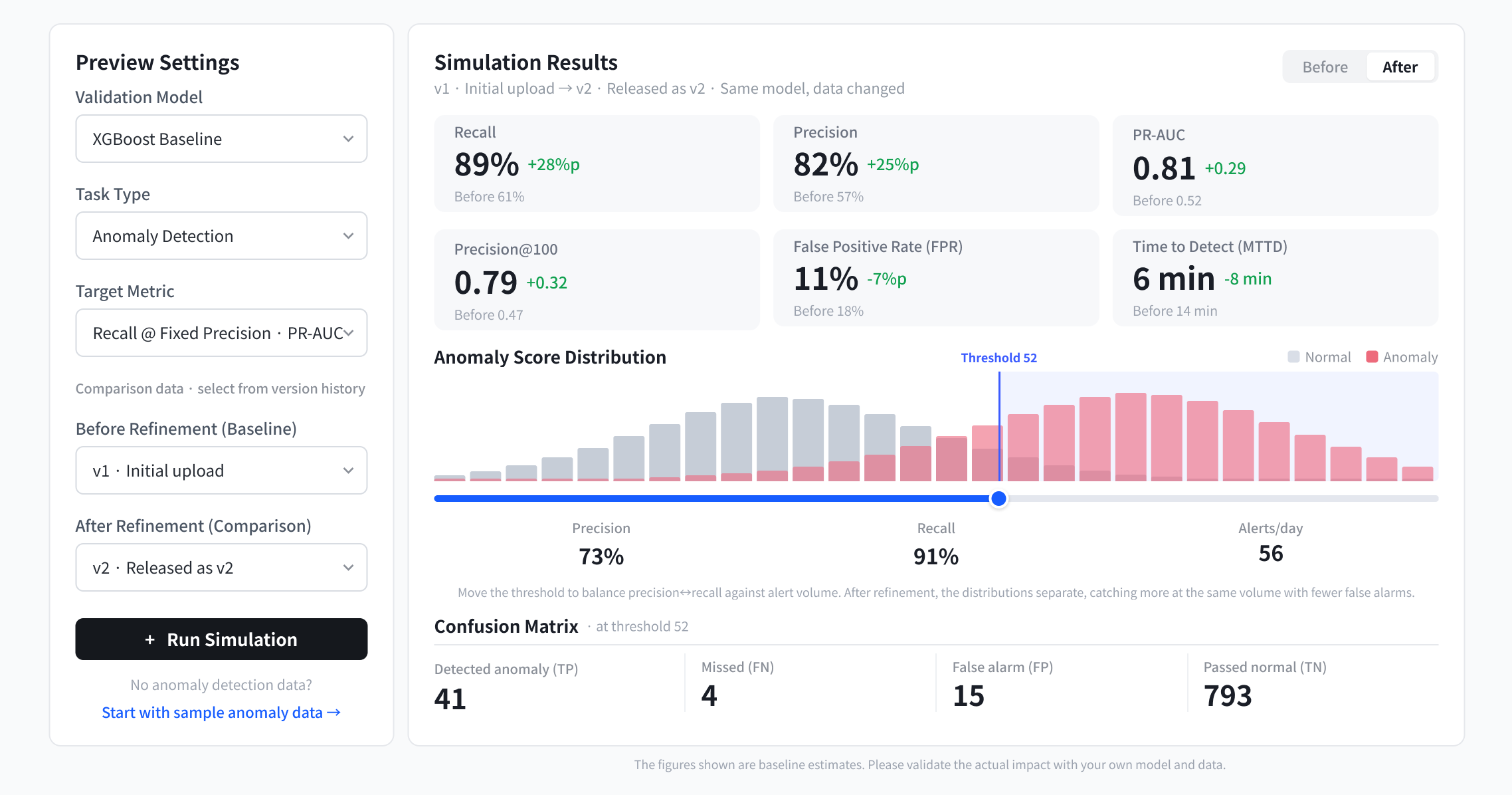
Proof Run
전후 데이터를 베이스라인 모델에 돌려 AI-Ready 준비의 예상 효과를 미리 봅니다.
미리 보기 설정
XGBoost baseline
이진 분류
Recall @ fixed precision
스냅샷 vs AI-Ready Release
시뮬레이션 결과
Before · 원본 데이터
거래 승인
Recall61%
F10.64
False positive18%
After · AI-Ready
검토 대상 표시
Recall89%
F10.78
False positive11%
예상 향상폭
Recall+28 pts
F1+0.14
False positive-31%
아직 모델이 없으신가요?
표준 베이스라인 모델로 즉시 확인하세요. 표시된 수치는 베이스라인 추정치입니다. 실제 효과는 직접 모델로 검증하세요.
Optimize for My Model
AI-Ready 준비 우선순위를 내 모델의 목표 지표와 평가 데이터에 맞게 조정합니다.
평가 데이터셋 업로드
정답 레이블이 포함된 평가 데이터셋을 연결하세요.
예측 결과 업로드
현재 운영 모델의 예측 출력을 업로드하세요.
MCP로 모델 연결
Claude Code 또는 사내 환경에서 모델 실행을 연결하세요.
✓ 자동 감지됨 사기 탐지 · 목표 지표: Recall @ 95% precision · 현재 점수: 73%
최적화 플랜
PII 컬럼 처리
민감 컬럼을 치환해 모델 입력을 안정화합니다.
중복 레코드 제거
학습을 편향시키는 중복을 제거합니다.
스키마 컨텍스트 표준화
컬럼 의미를 정규화하고 태스크 의도에 연결합니다.
노이즈 컬럼 제거
사용하지 않는 컬럼을 제거해 토큰 비용과 노이즈를 줄입니다.
일반적인 정제가 아닙니다. 내 모델의 성능을 가장 크게 끌어올리는 준비를 영향 순으로 우선합니다. 향상폭 수치는 베이스라인 추정치이며, 검증된 향상폭은 내 모델에서 재현됩니다.
AI-Ready Refinement
데이터 값과 분포를 바로잡고, AI가 데이터를 쓸 수 있도록 맥락을 더합니다.
피처 파생 및 증강
구간화와 범주화로 새 컬럼을 만들고, 열 간 연산으로 복합 신호를 더합니다.
민감한 데이터 탐지 및 치환
민감한 값을 식별할 수 없는 값으로 대체합니다.
결측값 처리
의미 있는 결측 패턴은 신호로 보존하고, 나머지 간극은 통계적 방법으로 보완합니다.
이상치·분포·범주 정제
이상치를 식별하고 분포·범주의 왜곡을 바로잡아, 모델이 안정적으로 학습할 수 있게 만듭니다.
데이터 증강·클래스 균형 조정
소수 클래스의 샘플을 생성해 보강하고, 클래스 간 비율 차이를 정상 범위로 조정합니다.
신호가 약한 열 제거
중요도 점수가 낮은 열, 예측 결과를 오염시킬 수 있는 열을 선택적으로 제거합니다.
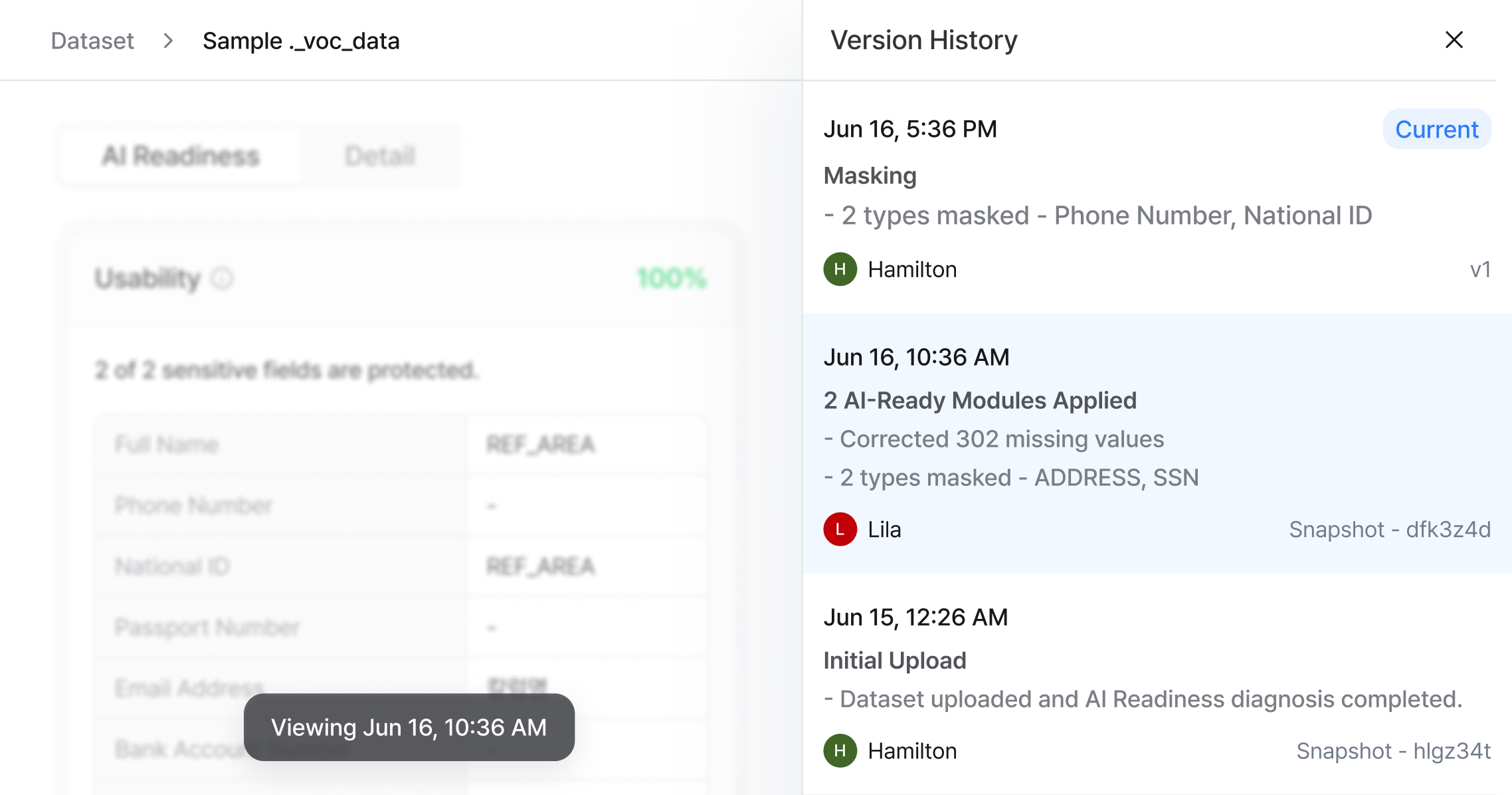
Release & Run Binding
AI-Ready 결과를 버전이 박힌 Release State로 고정합니다. 모든 AI 실행이 여기에 연결됩니다.
새 릴리스
v4로 게시됩니다.
버전 기록
Jul 19, 4:40 AM
민감 필드 처리. product_category 컬럼 의미 추가. v2 대비 분포 안정.
Jul 16, 11:18 AM
클래스 균형 적용 · 저신호 컬럼 제거
Jul 16, 10:16 AM
최초 업로드
v3 릴리스 완료.
Verify via Claude MCP
말로 증명하지 않습니다. 동일한 모델, 시드, 분할로 사내 환경에서 직접 다시 실행해 확인하세요.
Portable Proof Kit
before_snapshot.csv준비됨
after_release.csv준비됨
change_manifest.json준비됨
comparison_harness.py준비됨
eval_config.json내보내기 가능
README.md내보내기 가능
Claude MCP
Open Claude Code
검증 준비됨
Claude Code에서 전후 데이터를 실행해 결과를 재현하세요.
단순 데이터 다운로드가 아닙니다. Change Manifest, Harness, Eval Config를 묶은 재현 가능한 실험 키트를 내보냅니다.
실증
화면으로 직접 확인하는 증거.
테스트를 통과한 AI가 운영에서도 멈추지 않는 이유를 화면 세 장으로 보여드립니다.
증명을 실행하는 세 가지 방법.
원하는 방식으로 고르세요. 직접 모델을 가져오거나, 지표에 맞게 준비를 조정하거나, 직접 다시 실행하세요.
베이스라인으로 미리 보기
아직 모델이 없으신가요? Syntitan의 베이스라인 모델이 전후 성능을 즉시 비교합니다.
내 모델에 맞게 최적화
Syntitan이 목표 지표, 평가셋, 모델에 맞춰 데이터 준비 방향을 조정합니다.
Claude MCP로 검증
전후 데이터, 변경 매니페스트, 하네스를 내보내 사내 환경에서 다시 실행하세요.
플랫폼
DTS와 LLM Capsule은 Syntitan 하나로 움직입니다.
Syntitan이 플랫폼이고, DTS와 LLM Capsule은 그 핵심 역량입니다.
세 개의 도구가 아니라 하나의 플랫폼으로 AI를 실제 운영 단계까지 끌어올립니다.


플랫폼
Syntitan
데이터 준비도를 진단하고, 고정된 AI-Ready 상태를 릴리스하고, 모든 실행을 거기에 연결합니다. 그래서 데모에서 됐던 게 운영에서도 유지됩니다.
DTS
제한되거나, 불균형하거나, 갇힌 데이터를 AI-Ready 데이터셋으로 다시 만듭니다. 못 쓰던 데이터가 모델이 쓸 수 있는 데이터가 됩니다.
더보기LLM Capsule
민감 데이터의 맥락을 보존한 채 AI를 돌리고, 결과는 사내 워크플로우 안에서 업무에 쓸 수 있게 재구성합니다.
더보기플랫폼이 이 둘을 작동시키는 방식
검증
DTS와 Capsule이 만든 데이터가 정말 AI-Ready인지 6축으로 채점하고, 운영 전에 내 모델에서의 향상을 미리 봅니다.
검증 가능한 데이터 상태
그 데이터 상태를 버전으로 고정해 모든 실행을 그대로 재현합니다. Release · Run Binding · Diff · Reproduce.
에이전트 연결
검증된 데이터 상태를 Claude MCP로 모든 에이전트에 넘겨, 출력이 믿을 수 있는 데이터에 묶이게 합니다.
에이전트 분석 모듈
추측이 아니라, 준비된 데이터 위에서 도는 에이전트.
일반 에이전트는 추측합니다.
Syntitan 에이전트는 검증된 데이터 위에서 맥락까지 갖춰 돌아갑니다. 에이전트는 별도 제품이 아니라 그 데이터 상태 위에서 도는 응용입니다.
실제 응답 분포를 재현하는 10만 개의 합성 페르소나
실제 설문을 돌리기 전에, 10만 개 합성 페르소나로 응답을 미리 시뮬레이션하고 행동 패턴을 분석합니다.
결과 리포트
어떤 고객에 집중할지, ROI까지 시뮬레이션
행동과 인구통계로 고객을 세분화하고 ROI 기반 전략을 시뮬레이션합니다.
결과 리포트
고객이 떠나기 전에 이탈 신호를 포착
행동 신호로 이탈 위험 고객을 식별하고, 이탈을 예측하고, 리텐션 전략을 제안합니다.
결과 리포트
매출과 이탈 영향을 사전 검증하는 출시 가격 시뮬레이션
가격 민감도를 분석하고 매출과 이탈 영향을 고려한 출시 가격을 추천합니다.
결과 리포트
이미 모델이나 에이전트가 있으신가요?
API 연결로 AI-Ready 전후 성능을 비교합니다.
아키텍처 리뷰 신청필요한 에이전트가 없으신가요?
분석 시나리오를 알려주시면 맞춤 에이전트를 설계해 드립니다.
아키텍처 리뷰 신청
적합성
AI 데이터 스택에서 Syntitan의 위치
Syntitan은 팀이 이미 쓰는 도구를 대체하지 않습니다. 엔터프라이즈 데이터와 AI 실행 사이의 빠진 단계를 채웁니다.
한 줄로 보는 Syntitan
원본 기업 데이터에서, 운영 AI가 바로 돌 수 있는 고정되고 추적 가능한 AI-Ready 상태까지 가는 경로입니다.
-
데이터 플랫폼
엔터프라이즈 데이터를 저장합니다: 웨어하우스, 레이크하우스, 파이프라인.
Syntitan이 더하는 것 그 위의 AI-Ready 계층: 점수 매기고, 고치고, 고정합니다.
-
데이터 품질 도구
문제를 탐지합니다: null 비율, 타입 오류, 스키마 드리프트.
Syntitan이 더하는 것 정말 중요한 판정: 이 데이터로 AI가 돌아가는지, 무엇이 막고 있는지.
-
옵저버빌리티 도구
파이프라인, 모델, 시스템에서 무언가 바뀌었음을 탐지합니다.
Syntitan이 더하는 것 어떤 데이터가 바뀌었는지: 두 상태를 비교하고, 되던 상태로 되돌립니다.
-
에이전트 도구
데이터 위에서 에이전트와 에이전트 워크플로우를 실행합니다.
Syntitan이 더하는 것 에이전트가 돌 준비된 데이터. 답이 추측이 아니라 근거에서 나옵니다.
-
민감 데이터 변환 도구
합성 변환과 민감 데이터 준비.
Syntitan이 더하는 것 더 긴 경로의 한 걸음: 진단하고, 고치고, 릴리스하고, 모든 실행을 추적합니다.
활용 사례
팀이 시작하는 지점
어디서 시작하든, 경로는 같은 Release State로 모입니다.
AI가 망가졌을 때, 원인이 데이터인지 실행인지 어떻게 아시나요?
Run Binding, Release State, Diff로 기억이 아니라 증거에서 원인을 좁힙니다.
이 결과가 어떤 데이터 상태에서 나왔는지 증명할 수 있나요?
모든 리스크 분석이 Release State에 연결되고, 내부 검토가 들여다볼 수 있는 버전 기록이 남습니다.
지난 캠페인에 쓴 세그먼트를 그대로 다시 만들 수 있나요?
캠페인 데이터 상태를 릴리스하고 버전 간 전후 변화를 비교합니다.
지난달 분석을 재현하는 데 얼마나 걸리나요?
반복 분석이 같은 Release State에 붙어 있어, 재현은 재구축이 아니라 클릭 한 번입니다.
예측 결과가 분기마다 뚜렷한 이유 없이 바뀌나요?
민감한 인사 데이터를 보호된 경로로 준비하고, 분석 상태를 릴리스한 뒤, 분기별로 비교합니다.
FAQ
자주 묻는 질문
Syntitan은 AI-Ready Data Platform입니다. 데이터가 AI에 쓸 준비가 됐는지 점수로 진단하고, 막는 원인을 고치고, 그 결과를 버전이 붙은 Release State로 고정한 뒤, 모든 AI·에이전트 실행을 그 데이터까지 되짚을 수 있게 묶어 줍니다.
기업 데이터를 AI에 쓸 수 있게 준비하고, 그 상태를 유지해 주는 플랫폼입니다. 준비도 채점, 데이터·맥락 보강, 민감 데이터 준비, 그리고 운영 실행이 되짚어 갈 고정된 데이터 상태까지 담당합니다.
대부분의 기업 데이터는 아직 준비되지 않았습니다. Syntitan은 활용성·무결성·맥락·추적성 전반에서 AI를 위한 데이터 준비도를 진단하고, 데이터를 몇 주씩 정리하기 전에 모델·에이전트 사용을 막는 구체적인 갭을 보여줍니다.
네 단계입니다. 여섯 기준으로 준비도를 진단하고, 값과 맥락을 고치고, 고정된 AI-Ready 상태로 릴리스한 뒤, 모든 모델·에이전트 실행을 그 상태에 묶습니다.
AI Readiness Qualification은 데이터를 AI 모델이나 에이전트가 신뢰성 있게, 추적 가능하게 쓸 수 있는지 점검합니다. 활용성·무결성·맥락·일관성·재현성·추적성 전반의 갭을 드러냅니다.
AI-Ready Refinement는 데이터 값·분포·클래스 균형을 고치고, AI 시스템이 데이터의 의미를 이해하는 데 필요한 맥락을 더합니다.
Release State는 고정된 AI-Ready 데이터 상태입니다. 한 번 릴리스되면 분석·에이전트 실행·운영 검토의 기준점이 됩니다.
Run Binding은 모든 AI·에이전트 실행을 그 실행에 사용된 Release State에 연결합니다.
Diff는 두 Release State를 비교해 둘 사이에 무엇이 바뀌었는지 좁힙니다. Reproduce는 이전 데이터 상태를 복원해 팀이 증거에서 조사할 수 있게 합니다.
Syntitan은 실시간 프로덕션 데이터를 릴리스된 AI-Ready 기준선과 비교해, 어떤 필드와 분포가 움직였는지 드러낼 수 있습니다.
Syntitan 에이전트와 에이전트 워크플로우는 원본 파일이 아니라, 의미적 맥락이 붙은 검증된 데이터 기반 상태 위에서 실행됩니다. 그 출력은 모든 팀이 쓰는 동일한 Release State에 묶여 있습니다.
데이터 플랫폼은 데이터를 저장·처리합니다. 데이터 품질 도구는 이슈를 감지합니다. 옵저버빌리티 도구는 무언가 바뀌었음을 감지합니다. Syntitan은 이들과 AI 실행 사이에 자리합니다. 데이터가 준비됐는지 검증하고, 데이터와 의미적 맥락을 개선하며, 상태를 Release State로 고정하고, 모든 AI·에이전트 실행을 그 상태에 묶어둡니다. 다른 도구는 설명하거나 감지하지만, Syntitan은 준비합니다.
선정된 디자인 파트너 대상으로, Syntitan은 전체 평가를 돌리기 전에 내부 데이터가 목표 모델에 필요한 신호와 맥락을 갖췄는지 미리 살펴볼 수 있습니다.
지금 AI는 어떤 데이터 상태 위에서 돌고 있나요?
대부분의 팀은 답하지 못합니다. 한 번만 업로드하면 Syntitan이 답을 줍니다.