
By Bae Ho, Founder & CEO, CUBIG Corp. · Updated June 2026.
Agent-ready data is enterprise data that carries the business meaning, access conditions, and freshness an autonomous agent needs to act on a value, not just text the agent can retrieve. A single model call can tolerate thin context, because a person reads the one answer it returns. An agent that chains ten steps cannot: it carries each misreading into the next decision, with no one in the loop to catch it.
Enterprise AI adoption keeps stalling at the same seam: the step from a working demo to AI in production. The agentic wave is hitting that seam harder. Gartner predicts that over 40% of agentic AI projects will be canceled by the end of 2027, pointing to escalating costs, unclear business value, and inadequate risk controls. That sits on top of a problem Gartner had already flagged: it expects organizations to abandon 60% of AI projects through 2026 for want of AI-ready data, and its read of the failures is blunt: the data foundation is usually the issue, not the algorithm. An agent is only as reliable as its reading of the data, and it reads that data on every step of its run, usually with no one checking.
This article sets out what semantic context is for an agent, why an agent raises the bar an ordinary model set, why retrieval and a bigger model do not close the gap, and how to tell whether your own data carries enough context for an agent to act on.
Why an agent raises the bar a model set
A model called once gets a single look at the data and returns one answer. A person reviews it. If the reading was off, the error stops there.
An agent works through a loop instead. It reads the data, decides, calls a tool, reads what comes back, decides again, and keeps going, usually with no human between the steps. Every decision rests on how it read the values in front of it. When that reading is wrong because the meaning behind a value was missing, the agent does not stop to check. It acts on the wrong reading and feeds the result into its next step.
Picture an agent reconciling invoices. One column holds an amount, and a handful of rows are blank because those invoices were never issued, not because the amount was zero. A human would know that. The agent reads the blanks as zeros, marks the accounts as paid in full, and moves on to issue refunds against the difference. A single misread at step one became a wrong financial action four steps later, and nothing in the chain flagged the moment it went off.
Inaccuracy is already the consequence enterprises report most: McKinsey found that 51% of organizations using AI have hit at least one negative consequence, with inaccuracy at the top of the list. An agent multiplies that one failure down its chain rather than containing it to a single output.
What an agent needs to read: meaning, permission, freshness
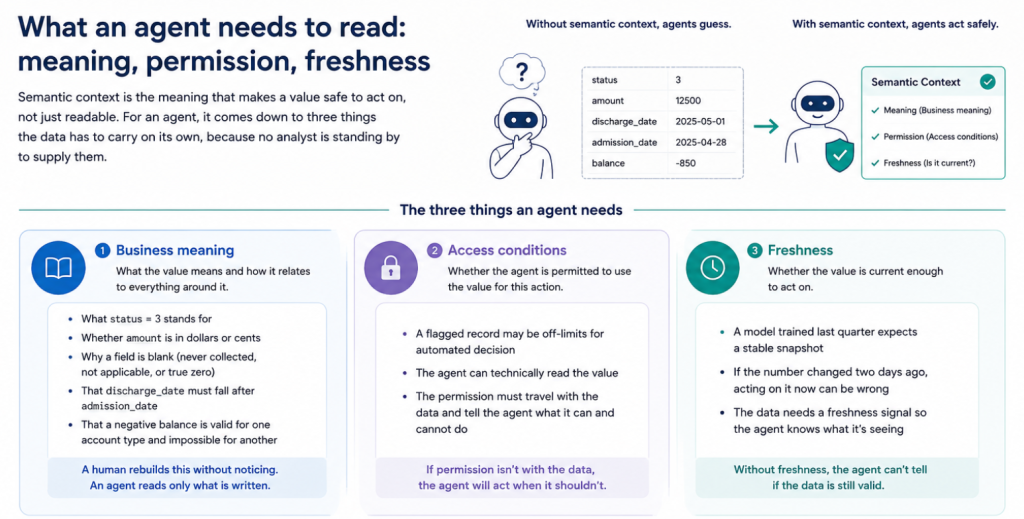
Semantic context is the meaning that makes a value safe to act on, not just readable. For an agent, it comes down to three things the data has to carry on its own, because no analyst is standing by to supply them.
Business meaning. What a value represents and how it relates to everything around it: what status = 3 stands for, whether amount is in dollars or cents, why a field is blank (never collected, not applicable, or a true zero), that discharge_date must fall after admission_date, and that a negative balance is valid for one account type and impossible for another. A human analyst rebuilds most of this without noticing. An agent reads what is written, and only what is written.
Access conditions. Whether the agent is permitted to use this value for this action. A person knows a flagged record is off-limits for an automated decision. An agent sees a value it can technically read and acts on it, unless the permission travels with the data and tells it not to.
Freshness. Whether the value is current enough to act on. A model trained last quarter expects a stable snapshot, but an agent acting in real time on a number that went stale two days ago makes a confident, outdated call. Without a freshness signal on the data, the agent has no way to know the difference.
Miss any one of the three and the agent still runs. It runs on a reading that meaning, permission, or freshness would have corrected.
Where that context disappears

Most enterprise data for AI moves through a bronze, silver, gold pipeline. Each promotion makes the data cleaner and more consistent, and along the way it strips out the context an agent depends on. The loss happens in ordinary steps, each defensible on its own:
- A blank is imputed to the column mean, so “never measured” and “average” collapse into the same number, and the agent can no longer separate a real reading from a filled gap.
- A field is generalized for compliance, turning a precise code into a broad band. The column clears its privacy check while the distinction the agent needed to route its next action is gone.
- A column is renamed or merged during a schema cleanup, and the relationship it held to another field is no longer recorded anywhere the agent can read.
None of these is a mistake. Each is correct hygiene for a warehouse. The trouble is that what they remove is never written back into the data, so the table still looks complete while the meaning behind it has left. A model trained once might absorb that loss as a few points of accuracy. An agent compounds it across every step of its run.
| A single model call | An autonomous agent | |
|---|---|---|
| Reads the data | Once | Repeatedly, across steps |
| Human between steps | Usually, to review the output | Usually none |
| Effect of a misreading | Contained in one answer | Compounds into later actions |
| Fills missing context from | The person reviewing the result | Nothing; reads only what is written |
| Needs meaning inside the data | Helpful | Required |
Why retrieval and a bigger model don’t close the gap
The common fix for “the agent lacks context” is to bolt on retrieval: give the agent a vector store and let it pull in documents at run time. Retrieval-augmented generation (RAG) helps, and it is worth doing. It does not solve the problem this article describes.
RAG improves what an agent can find. It says nothing about whether what it finds is current, permitted, or trusted by the business. A retriever will return a deprecated schema doc, a number from a table the agent is not cleared to act on, or a definition that was true two reorganizations ago. The text comes back. The conditions that make it safe to act on do not come back with it.
A bigger model does not close the gap either. A larger model reasons better over the context it is given; it cannot supply meaning, permission, or freshness the data never carried. When the underlying value is ambiguous or stale, more reasoning produces a more confident wrong answer, not a right one. This is the part that survives better models and better retrieval: the conditions have to be attached to the data itself, upstream of both.
A quick check: is your data agent-ready?
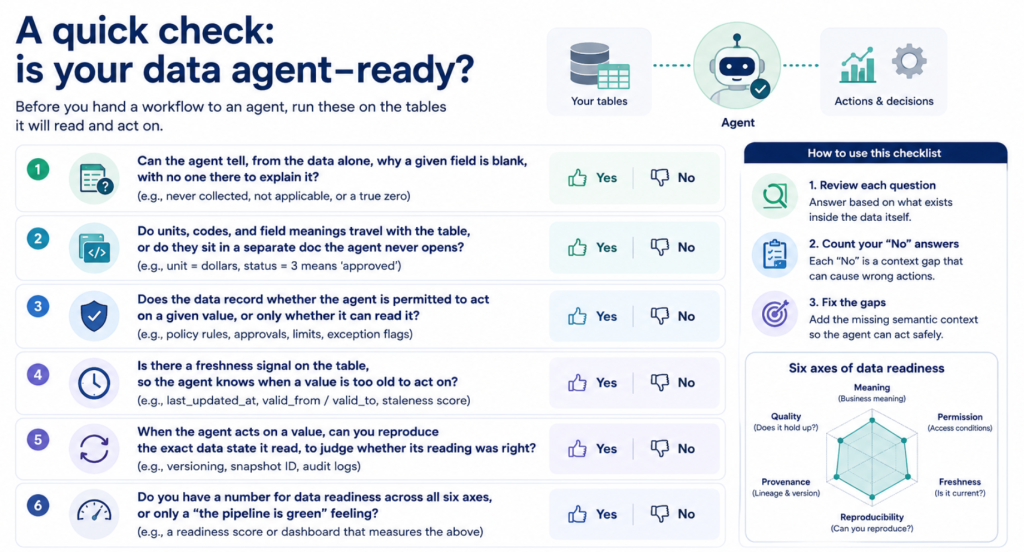
Before you hand a workflow to an agent, run these on the tables it will read and act on:
- Can the agent tell, from the data alone, why a given field is blank, with no one there to explain it?
- Do units, codes, and field meanings travel with the table, or do they sit in a separate doc the agent never opens?
- Does the data record whether the agent is permitted to act on a given value, or only whether it can read it?
- Is there a freshness signal on the table, so the agent knows when a value is too old to act on?
- When the agent acts on a value, can you reproduce the exact data state it read, to judge whether its reading was right?
- Do you have a number for data readiness across all six axes, or only a “the pipeline is green” feeling?
If the answers run to “no,” the limit on the agent is the context missing from the data it reads, not the quality of its reasoning.
Context is one of the six readiness axes
Preparing data for AI agents starts with measurement; “ready” only means something if you can measure it. Syntitan scores enterprise data on six readiness axes, and Context is the one this article is about: does the meaning, permission, and freshness a model or agent needs travel with the data? Clean data often scores well on Integrity and Usability while scoring low on Context, which is the exact profile that passes review and then misleads an agent in production. The full set, including Reproducibility and Traceability, is unpacked in What Is AI-Ready Data?.
For an agent, two of those axes work as a pair. Context lets the agent read the data correctly on any single run. Reproducibility lets you return to the exact state it read when a decision it made gets questioned, so you can see whether the data or the agent was at fault. That second axis carries more weight as trust thins: in Stack Overflow’s 2025 survey, more developers distrust the accuracy of AI output (46%) than trust it (33%). An agent that cannot show the data behind a decision leaves a skeptical team no way to check it, and the rollout stalls there.
Where Syntitan fits
Syntitan is the AI-Ready Data Platform that closes this gap. The front of the workflow diagnoses the six axes and rebuilds what blocks execution while preserving the structure and context that cleaning tends to drop, so the meaning an agent needs stays attached to the data. The back fixes that data as a reproducible state, so every agent run binds to something you can diff and return to when you need to explain a decision it made. Making data ready and keeping it reproducible is the job of an AI-ready data operating layer: the missing layer between data management and AI execution.
Any performance figure you see is representative until you reproduce it. Validated results come from your own agents, on your own data, in your own environment, not from a benchmark slide.
