
Databricks built one of the strongest governance layers in the market with Unity Catalog. It gives an enterprise a single way to govern data and AI assets across the lakehouse: access control, lineage, classification, and policy that reach over tables, models, and now the operational data that Lakebase brings onto the platform. If the job is to govern a whole data estate from one place, Databricks does that job well. Governing the estate is not the same as reproducing a run; the latter, as NeurIPS-led work notes, requires obtaining the same result with the same code and data.
Teams line Databricks up against Syntitan because both speak the language of AI readiness, and a few Databricks features look adjacent to what Syntitan does. Put the two side by side and they answer different questions, on different layers.
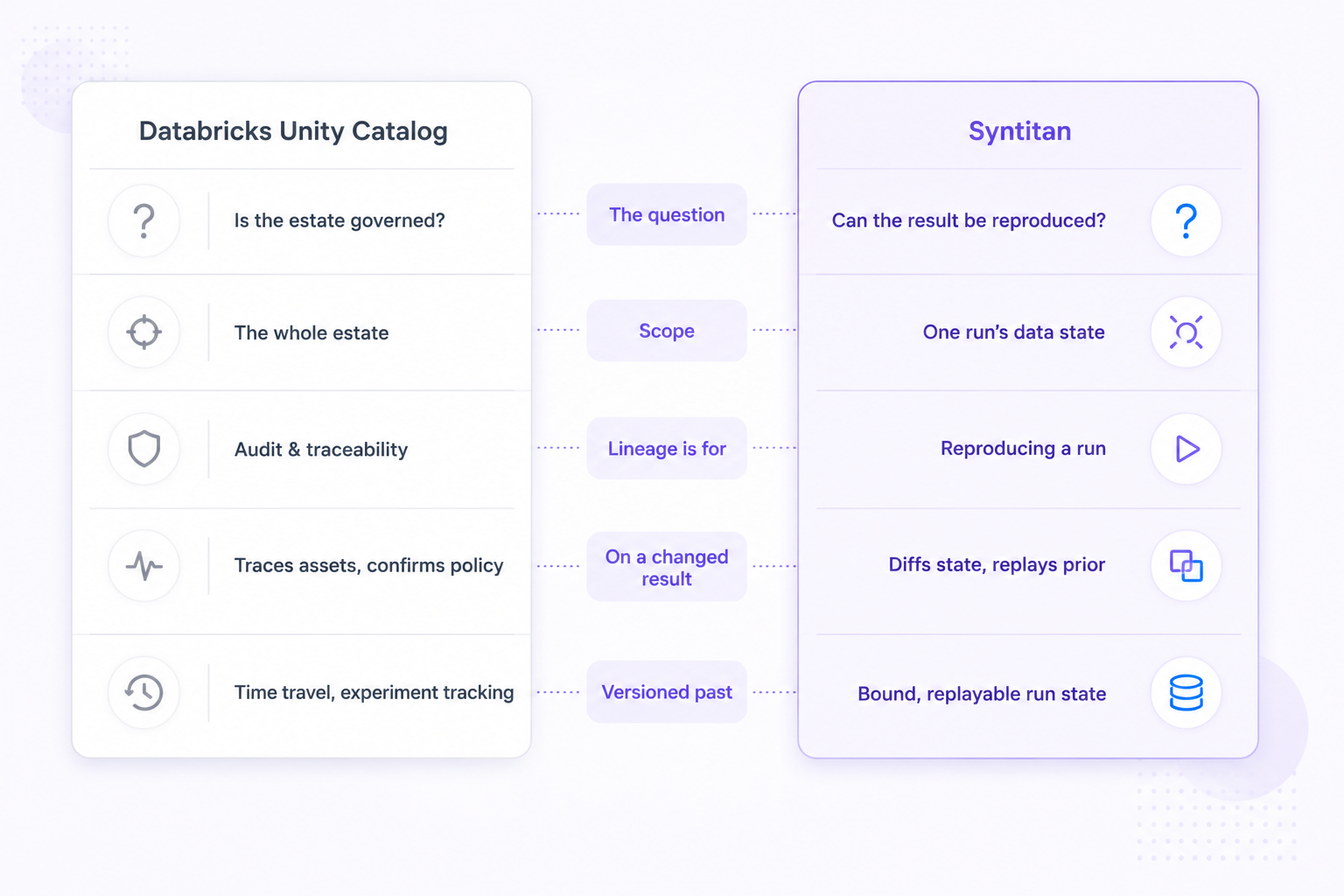
Unity Catalog governs the whole data estate. Syntitan binds and reproduces the state behind a single AI run.
Those are claims on different layers of the stack. Unity Catalog operates over the estate: the catalog of tables and models, the policies that apply to them, the lineage of where data and assets came from. Syntitan operates over a single AI run: it captures and versions the exact data state a model executed on, so that state can be compared against a later one, replayed, and the result reproduced. Reproducing ML results is a known systemic problem: one review found errors affecting 329 papers across 17 fields, often traced to data leakage.
A word on Lakebase
Lakebase is worth naming, because at a glance it looks like Databricks moving onto Syntitan’s ground. It is not. Lakebase is a serverless operational database, a place for applications and agents to read and write transactional data on the same platform as the analytics. It stores live data and serves it fast. That is a real and useful addition. It is an operational store, not a readiness layer, and it does not capture, version, or reproduce the data state behind a specific AI run. Lakebase widens what Databricks governs. It does not change the layer the comparison turns on.
Where the line falls
The gap shows up the moment a result moves. A model ran last week and gave one answer. It runs this week on a refreshed table and gives another. Unity Catalog can show the lineage of the assets involved and confirm that policy held. It does not, on its own, tell you which data state the working run depended on, what changed between then and now, or how to reproduce the earlier result.
Databricks has pieces that sit near this, and they are worth being precise about. Delta tables support time travel, and MLflow tracks the parameters, metrics, and artifacts of a training run. Both are real, and both solve their own problems. Time travel rolls a table back to a past version. Experiment tracking records what a run was configured with. Unity Catalog is not built primarily around capturing the released data state a specific AI run used, binding it to that run, diffing it against a later one, and replaying it to reproduce the result. Storage-level versioning and experiment-level tracking sit on a different layer from run-level reproduction.
What reproduction takes
Reproduction is the outcome. It rests on a set of mechanisms that an estate governance layer is not built around. Syntitan captures and versions the exact data state behind an AI run, so a team can compare, replay, and reproduce results when conditions change. In practice that means:
Snapshot. The exact released state of the data a run executed on, captured at the moment it ran.
Versioning. That state held as a versioned release, not overwritten by the next refresh.
Diff. A clear comparison of what changed in the data between one run and the next.
Replay. The earlier state re-run on demand, so the prior result can be reproduced.
The shorter version
Unity Catalog governs a data estate from one place, across tables, models, and operational data, and it is strong at that. Syntitan captures and versions the data state behind an AI run, so the result can be compared, replayed, and reproduced when the data moves. Both are forms of AI readiness, for different questions. Most teams running models in production will want their estate governed and their runs reproducible, which is why these sit on top of each other rather than against each other.
