
Clean data passes type, null, duplicate, and compliance checks.
AI-ready data clears one more bar: a model can still learn from what’s left, and you can reproduce the exact data behind any result. Clean is a hygiene standard. AI-ready is an execution standard. The two get used as if they mean the same thing, and that confusion is where most enterprise AI pilots stall.
“Our data is clean” is usually true. It is also a common reason the AI still fails. The checks that make data clean and the properties that make it ready are different properties, and a dataset can have the first while lacking the second. This article sets out where they diverge, why the gap stays invisible until production, and how to tell which side of the line your own data is on.
What “clean” actually certifies
Cleaning earns its place. Bad data is expensive. IBM’s widely cited estimate put the cost of poor data quality in the U.S. at $3.1 trillion a year, and clearing that mess is what cleaning addresses. So clean is a real and useful standard. When a data team says a dataset is clean, they mean it has passed a set of checks:
- Types are correct, so a date is a date and a number is a number.
- Nulls are handled, either dropped or filled, so nothing downstream breaks on a missing value.
- Duplicates are removed, so a record is counted once.
- Compliance is satisfied, so identifiers are masked or generalized to clear privacy review.
Pass all four and the data is clean. It will load, it will join, it will populate a dashboard, and it will survive an audit of its handling. None of that is in dispute. The trouble is that every one of those checks is about the form of the data, not about whether the signal a model needs survived the process.

What cleaning quietly removes
Most enterprise data moves through a bronze, silver, gold pipeline. Each promotion makes the data cleaner and more consistent, and each promotion also strips out information a model was relying on. The loss happens in ordinary steps, each defensible on its own:
- A blank row is dropped or imputed. But a blank often carries meaning. A missing lab value can mean the test was never ordered, which is itself a signal. Drop the row and the model learns nothing was there; impute it to the column mean and the model learns something false. The “reason it was blank” leaves with the row, and nothing records that it left.
- A field is generalized for compliance. Age becomes a ten-year band; a date becomes a quarter. Each column passes its privacy check in isolation, while the relationship between columns that the model was learning from is broken.
- A column is normalized to a clean range. It becomes comparable across sources and loses its distribution. A bimodal column that told the model two distinct populations existed flattens into a smooth ramp.
None of these is a mistake. Each is correct hygiene. The problem is that what they remove is never written down. The data clears every check and reaches the model stripped of part of what made it useful, and the subtraction stays invisible until a model trained on the residue underperforms in production.
Clean is hygiene. Ready is whether a model can learn.
This is the core distinction. Clean asks: did the data pass its checks? AI-ready asks: can a model still learn from what’s left, and can you reproduce the state it ran on? A dataset can be spotless on the first question and unfit on the second.
| Clean data | AI-ready data | |
|---|---|---|
| Standard | Hygiene | Execution |
| Asks | Did it pass its checks? | Can a model learn from it, reproducibly? |
| Optimized for | Dashboards, reporting, audit of handling | Models, LLMs, and agents in production |
| Treats a blank as | A defect to remove or fill | Possible signal to preserve and label |
| Cares about distribution? | No, tidy categories are fine | Yes, the full distribution carries the signal |
| Cares about reproducibility? | No, the latest clean version is enough | Yes, every run binds to a fixed, returnable state |
A dashboard wants tidy categories and suppressed outliers. A model wants the full distribution, including the parts a human would dismiss as noise. So the same gold table that is ideal for a report can be the wrong input for a model, even though it is, by every check, clean.

The cost of getting this wrong is not theoretical. Gartner expects organizations to abandon 60% of AI projects through 2026 for want of AI-ready data, and reports that 63% of organizations either lack the data management practices AI needs or are unsure they have them.
McKinsey finds that 51% of organizations using AI have already hit at least one negative consequence, with inaccuracy the most common.
The mistrust runs downstream to the people building on the output: in Stack Overflow’s 2025 survey, more developers distrust the accuracy of AI answers (46%) than trust it (33%). Gartner’s own reading of the failures is blunt: the problem is usually the data foundation, not the algorithm.
The part “clean” never covers: a state you can return to
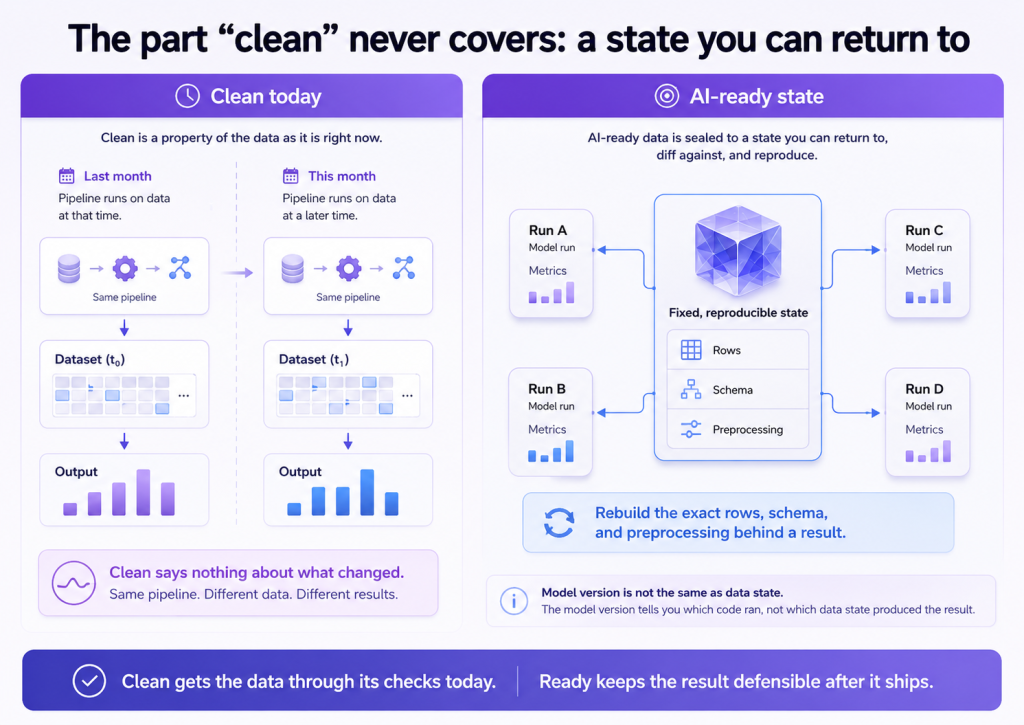
There is a second half to readiness that hygiene does not touch at all. Clean is a property of a dataset as it is right now. Production is not one moment.
The same pipeline, running on data that has shifted underneath it, produces different results next month, and “the data is clean” says nothing about why.
When a model that worked last month drifts this month, the team needs to answer one question fast: what changed between the run that worked and the run that didn’t.
Cleanliness cannot answer it. Only a fixed, reproducible state can. AI-ready data, in this sense, is data sealed to a state you can return to, diff against, and reproduce, so when output is questioned you can rebuild the exact rows, schema, and preprocessing the result came from.
Versioning the model is not the same thing: the model version tells you which code ran, not which data state produced the result.
This is why clean is necessary but not sufficient. Clean gets the data through its checks today. Ready keeps the result defensible after it ships.
How to tell the difference on your own data
A quick check before the next planning meeting:
- In your gold tables, can you still say why a given field is blank? If not, the context is already gone, even though the table is clean.
- When a model
drifts, can you diff the data state to see what moved? If not, you are debugging blind against a moving target. - Can you take any past result and reproduce the exact data it ran on? In a regulated setting, if you cannot, you may not be allowed to use that result at all.
- Do you have a number for readiness across all six axes, or only a “the pipeline is green” feeling?
If the answers run to “no,” your constraint is not model quality. It is the state of the data reaching the model, and that is a different problem with a different fix.
How AI-ready data gets measured
“Ready” only means something if you can measure it. Syntitan scores enterprise data on six readiness axes, which turns AI-ready from a claim into a number: Usability, Integrity, Context, Consistency, Reproducibility, and Traceability. Clean data tends to score well on Integrity and parts of Usability while scoring low on Context, Reproducibility, and Traceability. That is the profile of data that passes review and then fails in production. Each axis is unpacked in What Is AI-Ready Data?.
Where Syntitan fits
Syntitan is the AI-Ready Data Platform that handles both halves of the gap this article describes. The front of the workflow makes data AI-ready, diagnosing the six axes and rebuilding what blocks execution while preserving structure and the context that cleaning tends to drop. The back fixes that data as a reproducible state, so every AI or agent run binds to something you can diff and return to. That arc, make it ready and keep it reproducible, is the job of an AI-ready data operating layer: the missing layer between data management and AI execution.
Any performance figure you see is representative until you reproduce it. Validated lift comes from your own model, on your own data, in your own environment, not from a benchmark slide.

Related: PHI Masking vs Synthetic Data · What Is DTS? · What Is Sensitive AI Workflow Enablement?